반응형
실습 맛보기
Keras Tokenizer의 이해
In [14]:
# 샘플 문장
sample_text1 = "안녕하세요 저는 양혜림입니다."
sample_text2 = "★여러분 모두 만나서 반갑습니다!!!"
sample_text3 = "◆HI HELLO Nice To meet you ☆"
sample_text4 = "즐거운 하루 되세요. 저는 양혜림입니다."
In [15]:
# keras Tokenizer import 합니다.
from tensorflow.keras.preprocessing.text import Tokenizer
In [16]:
# word_index dic으로 저장 합니다.
# 해당 결과를 통해 어떻게 토크나이징이 되었는지 특징을 파악 가능합니다.
# 공백으로 분리, 일부 기호 삭제 됩니다.
# 빈도가 높은 순으로 index(숫자)가 생성이 됩니다.
# 토큰화 및 dic 생성
token=Tokenizer()
token.fit_on_texts([sample_text1, sample_text2, sample_text3, sample_text4])
dic = token.word_index
print(dic)
print(type(dic))
{'저는': 1, '양혜림입니다': 2, '안녕하세요': 3, '★여러분': 4, '모두': 5, '만나서': 6, '반갑습니다': 7, '◆hi': 8, 'hello': 9, 'nice': 10, 'to': 11, 'meet': 12, 'you': 13, '☆': 14, '즐거운': 15, '하루': 16, '되세요': 17}
<class 'dict'>
In [18]:
#샘플 문장을 숫자로 변환 해보겠습니다.
x = token.texts_to_sequences([sample_text1,sample_text2,sample_text3,sample_text4,])
print(x)
[[3, 1, 2], [4, 5, 6, 7], [8, 9, 10, 11, 12, 13, 14], [15, 16, 17, 1, 2]]
In [19]:
#새로운 문장을 숫자로 변환해 보겠습니다.
y = token.texts_to_sequences(["즐거운 양혜림입니다 룰루"])
print(y)
[[15, 2]]
실습 준비를 위한 코드 실행
모델의 Accuracy 와 Loss를 그려주는 그래프 정의
In [20]:
#그래프 그리기
import matplotlib.pyplot as plt
def graph(history):
#loss 값 설정.
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c= "red", label="Testset_loss")
plt.plot(x_len, y_loss, marker='.', c= "blue", label="Trainset_loss")
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(loc='upper left')
plt.show()
#loss 값 설정.
y_vacc= history.history['val_accuracy']
y_acc = history.history['accuracy']
plt.plot(x_len, y_vacc, marker='.', c= "red", label="Testset_accuracy")
plt.plot(x_len, y_acc, marker='.', c= "blue", label="Trainset_accuracy")
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend(loc='upper left')
plt.show()
실습 학습용 3. 텍스트 데이터 전처리 & AI모델링
STEP 0. 데이터 가져오기
In [21]:
# 데이터를 가져옵니다.
import pandas as pd
#df = pd.read_csv('/aihub/data/spam_data_category.csv')
df = pd.read_csv('/aihub/workspace/spam_data_category.csv')
In [22]:
# info 함수를 이용해서 데이터 정보를 확인합니다.
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 30000 entries, 0 to 29999
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 text 29977 non-null object
1 category 30000 non-null object
dtypes: object(2)
memory usage: 468.9+ KB
In [23]:
# head 함수를 활용해서 데이터 샘플을 확인합니다.
df.head(10)
Out[23]:
textcategory0123456789
| [Web발신]님오늘목돈도젼가능보유현금원pay구굴스토어가셔서검색요>신바탐코드 | 도박 |
| [Web발신]님오늘목돈도젼가능보유현금원pay구굴스토어가셔서검색요>신바탐코드 | 도박 |
| [Web발신]님오늘목돈도젼가능보유현금원pay구굴스토어가셔서검색요>신바탐코드 | 도박 |
| [Web발신][국.내.최.강]년차몌이저!!![⑦월임시]공개전환신규+만P!!!→sⓣv... | 도박 |
| [Web발신]비오는날운치있게thdqkrtk분위기살리고~살리고~JRJM | 도박 |
| MMS스팸신고프로토분석업체스코어픽티비김정윤과장입니다.다름이아니라개인번호가변경이되어문... | 기타스팸 |
| MMS스팸신고[Web발신](광고)안녕하십니까낳실제괴로움다잊으시고기를제밤낮으로애쓰는마... | 도박 |
| MMS스팸신고[Web발신](광고)기분좋은햇살만큼상쾌한오늘이당신에겐제일행복한하루가되었... | 도박 |
| MMS스팸신고(광고)기분좋은햇살만큼상쾌한오늘이당신에겐제일행복한하루가되었으면합니다~^... | 도박 |
| MMS스팸신고(광고)기분좋은햇살만큼상쾌한오늘이당신에겐제일행복한하루가되었으면합니다~^... | 도박 |
In [24]:
# category 데이터 분포를 확인합니다.
df['category'].value_counts()
Out[24]:
비대상 12008
기타스팸 11358
도박 5971
약품 663
Name: category, dtype: int64STEP 1. 데이터 클렌징
In [29]:
df['text'] = pd.DataFrame(df['text'].str.replace('MMS스팸신고',''))
df['text'] = pd.DataFrame(df['text'].str.replace('\[Web발신\]',''))
df['text'] = pd.DataFrame(df['text'].str.replace('\[WEB발신\]',''))
df['text'] = pd.DataFrame(df['text'].str.replace('KISA신고메시지',''))
df['text'] = pd.DataFrame(df['text'].str.replace('KISA신고',''))
df = df.dropna(axis=0)
df = df.drop_duplicates(keep='first', ignore_index=True)
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 25828 entries, 0 to 25827
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 text 25828 non-null object
1 category 25828 non-null object
2 nouns 25828 non-null object
dtypes: object(3)
memory usage: 605.5+ KB
STEP 2. 토큰화 및 Dictionary 생성
케라스 토크나이저를 이용해서 텍스트를 토큰화 하려면 문장에 띄어쓰기가 되어 있어야 합니다.그런데 본 학습 데이터는 띄어쓰기 처리가 되어 있지 않으므로 형태소 분석을 통해 명사를 추출후 공백으로 연결하여 띄어쓰기를 생성해 주도록 하겠습니다.
실습 2-1. 띄어쓰기 하기
In [26]:
# 한글 형태소 분석기인 konlpy 패키지를 설치합니다.
! pip install konlpy
Requirement already satisfied: konlpy in /usr/local/lib/python3.6/dist-packages (0.6.0)
Requirement already satisfied: lxml>=4.1.0 in /usr/local/lib/python3.6/dist-packages (from konlpy) (4.8.0)
Requirement already satisfied: JPype1>=0.7.0 in /usr/local/lib/python3.6/dist-packages (from konlpy) (1.3.0)
Requirement already satisfied: numpy>=1.6 in /usr/local/lib/python3.6/dist-packages (from konlpy) (1.19.5)
Requirement already satisfied: typing-extensions in /usr/local/lib/python3.6/dist-packages (from JPype1>=0.7.0->konlpy) (3.7.4.3)
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
In [30]:
# mecab 형태소 분석기를 불러옵니다.
from konlpy.tag import Mecab
mecab = Mecab()
리팩토링
(refactoring) 아래 코드를 apply, lambda 함수를 활용 하여, refactoring 해보세요.
In [31]:
#문제
df['nouns'] = ''
for i in range(len(df['text'])):
nouns_list = mecab.nouns(df['text'].loc[i])
nouns = " ".join(nouns_list)
df['nouns'].loc[i] = nouns
df.head()
Out[31]:
textcategorynouns01234
| 님오늘목돈도젼가능보유현금원pay구굴스토어가셔서검색요>신바탐코드 | 도박 | 님 오늘 목돈 젼 가능 보유 현금원 구굴 스토어 검색 바탐 코드 |
| [국.내.최.강]년차몌이저!!![⑦월임시]공개전환신규+만P!!!→sⓣv.net→SP | 도박 | 국 내 최 강 년차 월임 시 공개 전환 신규 |
| 비오는날운치있게thdqkrtk분위기살리고~살리고~JRJM | 도박 | 비오 날 운치 분위기 |
| 프로토분석업체스코어픽티비김정윤과장입니다.다름이아니라개인번호가변경이되어문자보내드리니문... | 기타스팸 | 프로토 분석 업체 스코어 픽 티비 김정윤 과장 개인 번호 변경 문자 문 사항 시이 ... |
| (광고)안녕하십니까낳실제괴로움다잊으시고기를제밤낮으로애쓰는마음어버이날을맞이하여다양한이... | 도박 | 광고 안녕 괴로움 고기 제 밤낮 마음 어버이날 이벤트 준비 입후 만 원 이용 스타 ... |
In [33]:
#(refactoring)
df['nouns'] = ""
df['nouns'] = df['text'].apply(lambda x:" ".join(mecab.nouns(x)))
df.head()
Out[33]:
textcategorynouns01234
| 님오늘목돈도젼가능보유현금원pay구굴스토어가셔서검색요>신바탐코드 | 도박 | 님 오늘 목돈 젼 가능 보유 현금원 구굴 스토어 검색 바탐 코드 |
| [국.내.최.강]년차몌이저!!![⑦월임시]공개전환신규+만P!!!→sⓣv.net→SP | 도박 | 국 내 최 강 년차 월임 시 공개 전환 신규 |
| 비오는날운치있게thdqkrtk분위기살리고~살리고~JRJM | 도박 | 비오 날 운치 분위기 |
| 프로토분석업체스코어픽티비김정윤과장입니다.다름이아니라개인번호가변경이되어문자보내드리니문... | 기타스팸 | 프로토 분석 업체 스코어 픽 티비 김정윤 과장 개인 번호 변경 문자 문 사항 시이 ... |
| (광고)안녕하십니까낳실제괴로움다잊으시고기를제밤낮으로애쓰는마음어버이날을맞이하여다양한이... | 도박 | 광고 안녕 괴로움 고기 제 밤낮 마음 어버이날 이벤트 준비 입후 만 원 이용 스타 ... |
In [34]:
# data_backup
df.to_csv('/aihub/data/spam_train_category_nouns.csv', index=False, encoding='utf-8-sig')
In [35]:
# nouns 컬럼을 text로 변경하고 기존 text 는 삭제 합니다.
df['text'] = df['nouns']
df = df[['text', 'category']]
df.head(10)
Out[35]:
textcategory0123456789
| 님 오늘 목돈 젼 가능 보유 현금원 구굴 스토어 검색 바탐 코드 | 도박 |
| 국 내 최 강 년차 월임 시 공개 전환 신규 | 도박 |
| 비오 날 운치 분위기 | 도박 |
| 프로토 분석 업체 스코어 픽 티비 김정윤 과장 개인 번호 변경 문자 문 사항 시이 ... | 기타스팸 |
| 광고 안녕 괴로움 고기 제 밤낮 마음 어버이날 이벤트 준비 입후 만 원 이용 스타 ... | 도박 |
| 광고 기분 햇살 오늘 당신 행복 하루 로비스트 인사 무엇 상상 이상 것 종제 제 | 도박 |
| 광고 기분 햇살 오늘 당신 행복 하루 로비스트 인사 무엇 상상 이상 것 종제 제 방... | 도박 |
| 광고 기분 햇살 오늘 당신 행복 하루 로비스트 인사 무엇 상상 이상 것 종제 제 방해 | 도박 |
| 광고 광고 홀딩스 브레인 파트 너스 박다정 차장 브레인 파트 너스 공시 전 세력 주... | 기타스팸 |
| 여름 더위 강타 신 폭풍 게임 호계동 최초 상륙 구사 임장 지하층 더위 입장 시 오... | 도박 |
In [37]:
# (옵션) 데이터 클렌징 작업을 한번 더 진행하겠습니다.
df = df.dropna(axis=0)
df = df.drop_duplicates(keep='first', ignore_index=True)
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 22301 entries, 0 to 22300
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 text 22301 non-null object
1 category 22301 non-null object
dtypes: object(2)
memory usage: 348.6+ KB
실습 2-2. 토큰화 및 dic 생성
실습맛보기에서 보여드렸던 keras Tokenizer 함수를 이용해서 문장을 토큰화 하고 dic 생성, 숫자열 변환처리 까지 진행해 보았습니다.형태소 분석기를 사용하는 것보다 쉽게 데이터 전처리를 할수 있어서 좋습니다.실습 1에서 수행 했던 데이터 전처리 과정을 복습하면서 실습해 보시면 좋을 것 같습니다.
In [38]:
# Tokenizer 를 import 합니다.
from tensorflow.keras.preprocessing.text import Tokenizer
(실습) keras Tokenizer를 활용하여, 문장을 토큰화 하고 각 토큰의 index를 dic으로 저장합니다.
In [42]:
dic = {}
token=Tokenizer()
token.fit_on_texts(df["text"])
dic = token.word_index
dic의 전체 사이즈를 확인합니다.word_size는 임베딩 레이어 설계시 중요한 요소이니 꼭 기억하셔야 합니다.
In [43]:
word_size = len(dic)
print("word_size: ",word_size)
word_size: 22838
STEP 3. 스팸 데이터 [x 값] 인코딩
Keras 에서 만든 dic을 이용해서 스팸 데이터를 숫자열로 변환하는 인코딩 작업을 진행합니다.Keras Tokenizer의 texts_to_sequences 를 이용하면 아주 간단하게 해결 됩니다.
(실습) texts_to_sequences 이용해 가지고 문장들을 숫자형태로 변환 후 x에 저장합니다.
In [46]:
x = token.texts_to_sequences(df["text"])
# print(x)
STEP 4. 패딩
문장의 최대 길이를 구해봅니다.
In [47]:
max_length = max([len(item) for item in x])
print(max_length)
40
In [48]:
from tensorflow.keras.preprocessing.sequence import pad_sequences
(실습) pad_sequences 이용해 패딩하세요.
In [49]:
padded_x = pad_sequences(x)
padded_x[:3]
Out[49]:
array([[ 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 392, 40, 2400, 1572, 22, 127, 2820, 11566,
959, 385, 11567, 221],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 470, 110, 635, 418, 1746, 4641,
20, 23, 1495, 201],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
5738, 132, 11568, 3098]], dtype=int32)STEP 5. 라벨 데이터 인코딩
라벨 데이터인 category 데이터가 도박, 약품, 기타스팸, 비대상 이렇게 문자입니다.모델이 처리 할 수 있도록 숫자형태로 변환이 필요합니다.카테고리 데이터는 Label Encdoer를 이용해 자동으로 0,1,2,3 로 변환 해보겠습니다.
실습 5-1. 라벨 데이터 인코딩
In [50]:
# sklearn LabelEncoder import
from sklearn.preprocessing import LabelEncoder
In [51]:
# e 변수에 LabelEncoder()를 정의합니다.
e = LabelEncoder()
In [52]:
# fit 함수를 이용해 category unique 한 카테고리 를 숫자에 매핑해봅니다.
e.fit(df['category'])
Out[52]:
LabelEncoder()In [53]:
# 실제 데이터를 trasform 함수를 이용해 변환 합니다.
Y = e.transform(df['category'])
In [54]:
# 데이터 확인
print(Y)
[1 1 1 ... 0 0 0]
In [55]:
Y[0:30]
Out[55]:
array([1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 0, 0, 0, 1, 1, 1, 0, 1, 0, 0, 3, 2,
2, 2, 1, 2, 2, 1, 2, 2])실습5-2. 라벨 데이터 원 핫 인코딩
카테고리 분류의 softmax 활성화 함수를 적용 하려면 Y 값이 숫자 0과 1로 이루어져 있어야 합니다. 즉 원-핫 인코딩 처리를 해야합니다.keras to_categorical 함수 를 이용합니다.
In [56]:
from tensorflow.keras.utils import to_categorical
In [57]:
# Y_encoded 변수에 Y 데이터를 원 핫 인코딩 하여 입력 하세요.
Y_encoded = to_categorical(Y)
In [58]:
# 데이터 확인
print(Y_encoded)
[[0. 1. 0. 0.]
[0. 1. 0. 0.]
[0. 1. 0. 0.]
...
[1. 0. 0. 0.]
[1. 0. 0. 0.]
[1. 0. 0. 0.]]
STEP 6. 데이터셋 나누기 및 저장하기
In [59]:
# 사이킷런 train_test_split 을 이용해서 학습과 검증에 사용할 데이터 셋을 나누어 보겠습니다.
# 학습셋 : X_train, y_train
# 검증셋 : X_test, y_test
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(padded_x, Y_encoded, test_size = 0.2, random_state = 1)
# 만들어진 데이터의 타입과 shape을 확인해 봅니다.
print("X_train shape:", X_train.shape)
print("y_train shape:", y_train.shape)
print("X_test shape:", X_test.shape)
print("y_test shape:", y_test.shape)
X_train shape: (17840, 40)
y_train shape: (17840, 4)
X_test shape: (4461, 40)
y_test shape: (4461, 4)
STEP 6. CNN - AI모델링 및 평가
실습 6-1. CNN 모델 설계하기
다중분류 하는 모델을 생성하기 위해 마지막 레이어와 모델 컴파인 부분만 변경 됩니다.다른 부분은 기존과 동일하게 사용하도록 하겠습니다.
In [60]:
# 케라스를 이용해서 CNN 모델을 설계합니다.
# CNN 모델 설계에 필요한 패키지를 import 합니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Activation, Embedding
from tensorflow.keras.layers import Conv1D, MaxPooling1D, Flatten
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
import os
import numpy as np
import tensorflow as tf
MODEL_DIR = './keras_model/'
if not os.path.exists(MODEL_DIR):
os.mkdir(MODEL_DIR)
modelpath = MODEL_DIR+"/keras_cnn_{epoch:02d}-{val_loss:.4f}-{val_accuracy:.4f}.hdf5"
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=1, save_best_only=True)
early_stopping_callback = EarlyStopping(monitor = 'val_loss', patience=3)
seed = 0
np.random.seed(seed)
tf.random.set_seed(3)
model = Sequential()
model.add(Embedding(word_size+1, 8, input_length = 40))
model.add(Dropout(0.5))
model.add(Conv1D(64, 5, padding='valid', activation = 'relu', strides=1))
model.add(MaxPooling1D(pool_size=4))
model.add(Flatten())
(실습) output layer 추가 하세요.activation 함수는 softmax, node = 4 입니다.
In [61]:
model.add(Dense(4, activation="softmax"))
(실습) 모델을 컴파일 합니다.loss 함수는 categorical_crossentropy 사용합니다. optimizer는 adam 을 사용, metric은 'accuracy' 으로 설정
In [62]:
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
In [63]:
#모델 요약 보기
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 40, 8) 182712
_________________________________________________________________
dropout (Dropout) (None, 40, 8) 0
_________________________________________________________________
conv1d (Conv1D) (None, 36, 64) 2624
_________________________________________________________________
max_pooling1d (MaxPooling1D) (None, 9, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 576) 0
_________________________________________________________________
dense (Dense) (None, 4) 2308
=================================================================
Total params: 187,644
Trainable params: 187,644
Non-trainable params: 0
_________________________________________________________________
In [64]:
# 위에서 설계한 모델에 데이터를 가지고 학습을 진행 합니다.
history = model.fit(X_train, y_train, batch_size = 100, epochs = 20, validation_data=(X_test, y_test), callbacks=[early_stopping_callback, checkpointer])
Epoch 1/20
179/179 [==============================] - 5s 25ms/step - loss: 1.0557 - accuracy: 0.5305 - val_loss: 0.5474 - val_accuracy: 0.7763
Epoch 00001: val_loss improved from inf to 0.54737, saving model to ./keras_model/keras_cnn_01-0.5474-0.7763.hdf5
Epoch 2/20
179/179 [==============================] - 4s 23ms/step - loss: 0.4749 - accuracy: 0.8131 - val_loss: 0.4047 - val_accuracy: 0.8449
Epoch 00002: val_loss improved from 0.54737 to 0.40473, saving model to ./keras_model/keras_cnn_02-0.4047-0.8449.hdf5
Epoch 3/20
179/179 [==============================] - 4s 23ms/step - loss: 0.3498 - accuracy: 0.8623 - val_loss: 0.3399 - val_accuracy: 0.8893
Epoch 00003: val_loss improved from 0.40473 to 0.33992, saving model to ./keras_model/keras_cnn_03-0.3399-0.8893.hdf5
Epoch 4/20
179/179 [==============================] - 4s 24ms/step - loss: 0.2630 - accuracy: 0.9091 - val_loss: 0.3031 - val_accuracy: 0.9005
Epoch 00004: val_loss improved from 0.33992 to 0.30313, saving model to ./keras_model/keras_cnn_04-0.3031-0.9005.hdf5
Epoch 5/20
179/179 [==============================] - 4s 23ms/step - loss: 0.1988 - accuracy: 0.9352 - val_loss: 0.2834 - val_accuracy: 0.9101
Epoch 00005: val_loss improved from 0.30313 to 0.28342, saving model to ./keras_model/keras_cnn_05-0.2834-0.9101.hdf5
Epoch 6/20
179/179 [==============================] - 4s 24ms/step - loss: 0.1715 - accuracy: 0.9456 - val_loss: 0.2701 - val_accuracy: 0.9162
Epoch 00006: val_loss improved from 0.28342 to 0.27011, saving model to ./keras_model/keras_cnn_06-0.2701-0.9162.hdf5
Epoch 7/20
179/179 [==============================] - 4s 24ms/step - loss: 0.1451 - accuracy: 0.9531 - val_loss: 0.2689 - val_accuracy: 0.9166
Epoch 00007: val_loss improved from 0.27011 to 0.26889, saving model to ./keras_model/keras_cnn_07-0.2689-0.9166.hdf5
Epoch 8/20
179/179 [==============================] - 4s 25ms/step - loss: 0.1283 - accuracy: 0.9601 - val_loss: 0.2683 - val_accuracy: 0.9166
Epoch 00008: val_loss improved from 0.26889 to 0.26831, saving model to ./keras_model/keras_cnn_08-0.2683-0.9166.hdf5
Epoch 9/20
179/179 [==============================] - 4s 25ms/step - loss: 0.1160 - accuracy: 0.9650 - val_loss: 0.2675 - val_accuracy: 0.9191
Epoch 00009: val_loss improved from 0.26831 to 0.26754, saving model to ./keras_model/keras_cnn_09-0.2675-0.9191.hdf5
Epoch 10/20
179/179 [==============================] - 4s 25ms/step - loss: 0.0998 - accuracy: 0.9691 - val_loss: 0.2741 - val_accuracy: 0.9202
Epoch 00010: val_loss did not improve from 0.26754
Epoch 11/20
179/179 [==============================] - 4s 24ms/step - loss: 0.0980 - accuracy: 0.9674 - val_loss: 0.2745 - val_accuracy: 0.9218
Epoch 00011: val_loss did not improve from 0.26754
Epoch 12/20
179/179 [==============================] - 4s 25ms/step - loss: 0.0851 - accuracy: 0.9733 - val_loss: 0.2849 - val_accuracy: 0.9197
Epoch 00012: val_loss did not improve from 0.26754
In [65]:
# save 함수를 사용해서 모델을 저장합니다.
model.save(MODEL_DIR+'keras_cnn.h5')
In [67]:
# graph 함수를 이용해서 epoch 별 loss와 accuracy를 출력하는 그래프를 그려봅니다.
graph(history)


STEP 7. LSTM - AI 모델링 및 평가
다중분류 하는 모델을 생성하기 위해 마지막 레이어와 모델 컴파일 부분만 변경 됩니다.다른 부분은 기존과 동일하게 사용하도록 하겠습니다.
In [68]:
# 케라스를 이용해서 LSTM 모델을 설계합니다.
# LSTM 모델 설계에 필요한 패키지를 import 합니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Embedding, Dropout
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
import os
import numpy as np
import tensorflow as tf
# 모델 저장 경로 설정
MODEL_DIR = './keras_model/'
if not os.path.exists(MODEL_DIR):
os.mkdir(MODEL_DIR)
# 모델 이름 설정
modelpath = MODEL_DIR+"/keras_lstm_{epoch:02d}-{val_loss:.4f}-{val_accuracy:.4f}.hdf5"
#체크 포인트 설정 : 학습 진행 중 모델을 저장하기 위한 설정
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=1, save_best_only=True)
#학습 중단 조건 설정 : monitor 지표가 더 나아 지지 않으면 학습을 중단함.
early_stopping_callback = EarlyStopping(monitor = 'val_loss', patience=3)
# seed 값 설정 (일정한 값이 나오도록 함.)
seed = 0
np.random.seed(seed)
tf.random.set_seed(3)
# 모델의 설계
model = Sequential()
model.add(Embedding(word_size + 1, 8, input_length = 40))
model.add(Dropout(0.5))
model.add(LSTM(100, activation = 'tanh'))
(실습) output layer 추가 하세요.activation 함수는 softmax, node = 4 입니다.
In [69]:
model.add(Dense(4, activation="softmax"))
(실습) 모델을 컴파일 합니다.loss 함수는 categorical_crossentropy 사용합니다. optimizer는 adam 을 사용, metric은 'accuracy' 으로 설정
In [70]:
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
In [71]:
#모델 요약 보기
model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 40, 8) 182712
_________________________________________________________________
dropout_1 (Dropout) (None, 40, 8) 0
_________________________________________________________________
lstm (LSTM) (None, 100) 43600
_________________________________________________________________
dense_1 (Dense) (None, 4) 404
=================================================================
Total params: 226,716
Trainable params: 226,716
Non-trainable params: 0
_________________________________________________________________
In [72]:
# 위에서 설계한 모델에 데이터를 가지고 학습을 진행 합니다.
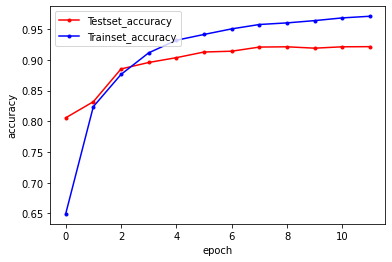
history = model.fit(X_train, y_train, batch_size = 100, epochs = 20, validation_data=(X_test, y_test), callbacks=[early_stopping_callback, checkpointer])
Epoch 1/20
179/179 [==============================] - 37s 198ms/step - loss: 1.0182 - accuracy: 0.5343 - val_loss: 0.5170 - val_accuracy: 0.8056
Epoch 00001: val_loss improved from inf to 0.51695, saving model to ./keras_model/keras_lstm_01-0.5170-0.8056.hdf5
Epoch 2/20
179/179 [==============================] - 36s 202ms/step - loss: 0.4686 - accuracy: 0.8172 - val_loss: 0.4033 - val_accuracy: 0.8319
Epoch 00002: val_loss improved from 0.51695 to 0.40325, saving model to ./keras_model/keras_lstm_02-0.4033-0.8319.hdf5
Epoch 3/20
179/179 [==============================] - 35s 195ms/step - loss: 0.3481 - accuracy: 0.8694 - val_loss: 0.3373 - val_accuracy: 0.8852
Epoch 00003: val_loss improved from 0.40325 to 0.33729, saving model to ./keras_model/keras_lstm_03-0.3373-0.8852.hdf5
Epoch 4/20
179/179 [==============================] - 35s 193ms/step - loss: 0.2656 - accuracy: 0.9079 - val_loss: 0.3026 - val_accuracy: 0.8958
Epoch 00004: val_loss improved from 0.33729 to 0.30257, saving model to ./keras_model/keras_lstm_04-0.3026-0.8958.hdf5
Epoch 5/20
179/179 [==============================] - 34s 189ms/step - loss: 0.2059 - accuracy: 0.9311 - val_loss: 0.2929 - val_accuracy: 0.9036
Epoch 00005: val_loss improved from 0.30257 to 0.29285, saving model to ./keras_model/keras_lstm_05-0.2929-0.9036.hdf5
Epoch 6/20
179/179 [==============================] - 35s 197ms/step - loss: 0.1849 - accuracy: 0.9405 - val_loss: 0.2759 - val_accuracy: 0.9128
Epoch 00006: val_loss improved from 0.29285 to 0.27590, saving model to ./keras_model/keras_lstm_06-0.2759-0.9128.hdf5
Epoch 7/20
179/179 [==============================] - 34s 190ms/step - loss: 0.1524 - accuracy: 0.9520 - val_loss: 0.2816 - val_accuracy: 0.9141
Epoch 00007: val_loss did not improve from 0.27590
Epoch 8/20
179/179 [==============================] - 34s 190ms/step - loss: 0.1363 - accuracy: 0.9584 - val_loss: 0.2579 - val_accuracy: 0.9209
Epoch 00008: val_loss improved from 0.27590 to 0.25791, saving model to ./keras_model/keras_lstm_08-0.2579-0.9209.hdf5
Epoch 9/20
179/179 [==============================] - 33s 184ms/step - loss: 0.1236 - accuracy: 0.9608 - val_loss: 0.2511 - val_accuracy: 0.9213
Epoch 00009: val_loss improved from 0.25791 to 0.25105, saving model to ./keras_model/keras_lstm_09-0.2511-0.9213.hdf5
Epoch 10/20
179/179 [==============================] - 36s 203ms/step - loss: 0.1066 - accuracy: 0.9646 - val_loss: 0.2513 - val_accuracy: 0.9191
Epoch 00010: val_loss did not improve from 0.25105
Epoch 11/20
179/179 [==============================] - 34s 190ms/step - loss: 0.1008 - accuracy: 0.9699 - val_loss: 0.2808 - val_accuracy: 0.9213
Epoch 00011: val_loss did not improve from 0.25105
Epoch 12/20
179/179 [==============================] - 33s 187ms/step - loss: 0.0923 - accuracy: 0.9711 - val_loss: 0.2657 - val_accuracy: 0.9215
Epoch 00012: val_loss did not improve from 0.25105
In [73]:
# save 함수를 사용해서 모델을 저장합니다.
model.save(MODEL_DIR+'\keras_lstm.h5')
In [74]:
# graph 함수를 이용해서 epoch 별 loss와 accuracy를 출력하는 그래프를 그려봅니다.
graph(history)

STEP 8. 활용하기
스팸문자 유형을 예측하는 함수 만들기
해당 모델을 이용해서 임의의 문장을 스팸인지 아닌지 예측해보는 함수를 만들어 봅시다.모델 학습 전에 텍스트 전처리 했던 것을 동일하게 진행 한 후에 모델 예측을 해야합니다.전처리 했던것을 떠올리면서 각 단계별로 함수를 만들어 보겠습니다.기존에 했던 것 보다 어떤 과정이 추가되었을지? 기억나시나요?띄어쓰기를 해주는 작업이 추가 되었습니다.!
In [75]:
from konlpy.tag import Mecab
from tensorflow.keras.preprocessing.text import Tokenizer
In [76]:
def preprocessing(text, dic, padding_size):
#1. 문자열 삭제
text = text.replace("MMS스팸신고","")
text = text.replace("[Web발신]","")
text = text.replace("[WEB발신]","")
text = text.replace("KISA신고메시지","")
text = text.replace("KISA신고","")
#2. 띄어쓰기 처리 (명사연결)
spacing_text = " ".join(mecab.nouns(text))
#3. 데이터 인코딩 (숫자로 변환)
token = Tokenizer()
token.word_index = dic
seqs = token.texts_to_sequences([spacing_text])
seq = seqs[0]
#4. 패딩
pad_seq = pad_sequences([seq], padding_size)
return pad_seq
In [79]:
text = "올여름더위를강타할신의폭풍게임드디어호계동최초상륙구사거리게임장지하1층더위식히러오세요입장"
In [82]:
preprocessing(text, dic, 40)
Out[82]:
array([[ 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 38, 266, 11574,
503, 3100, 546, 11575, 791, 6445, 373, 2531, 546,
6433, 323, 266, 585]], dtype=int32)In [84]:
y=model.predict_classes(preprocessing(text, dic, 40))
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/sequential.py:450: UserWarning: `model.predict_classes()` is deprecated and will be removed after 2021-01-01. Please use instead:* `np.argmax(model.predict(x), axis=-1)`, if your model does multi-class classification (e.g. if it uses a `softmax` last-layer activation).* `(model.predict(x) > 0.5).astype("int32")`, if your model does binary classification (e.g. if it uses a `sigmoid` last-layer activation).
warnings.warn('`model.predict_classes()` is deprecated and '
In [85]:
y
Out[85]:
array([1])In [86]:
e.inverse_transform(y)
Out[86]:
array(['도박'], dtype=object)In [88]:
model.predict(preprocessing(text, dic, 40))
Out[88]:
array([[2.0999479e-04, 9.9178642e-01, 4.8842514e-03, 3.1193318e-03]],
dtype=float32)