https://developer.nvidia.com/triton-inference-server
Triton Inference Server
Standardizes model deployment and delivers fast and scalable AI in production.
developer.nvidia.com
Triton Infernece Server는 Nvidia에서 딥러닝 모델을 배포하는 Triton Inference Server는 NVIDIA에서 개발한 오픈 소스 딥러닝 모델 추론을 위한 서버 프레임워크이다.
AI모델들의 배포를 위한만큼 Pytorch, TensorFlow, Onnx 등 여러 딥러닝 프레림워크의 모델 로드를 지원한다.

Inference를 위한 추론 서버 운영시, python기반 백엔드 프레임워크(django, flask, fastapi 등)와 조합하여 만들 수 있지만, 실시간 고속으로 처리해야 한다면 효율성 면에서 많이 떨어지게 될 것이다.
Triton Inference Server를 사용하게 된다면 다양한 딥러닝 모델을 고속으로 처리를 할 수 있도록 지원이 가능하다. 이러한 AI 생태계를 지원하는 여러 플랫폼이 있지만, 현재 AI 시스템의 90%이상은 NVIDA GPU를 사용하기 때문에 이러한 NVIDA PlaForm을 도입하는건 당연한 수순일 것이다.
TRITON SERVER 설치
TRITON SERVER는 ubuntu 환경에서 Docker로 설치가 가능하다.
필요사항
- nvidia GPU (Tensorrt fp16 지원을 받고 싶다면 텐서코어가 지원되어야 한다 텐서코어는 RTX시리즈, Jetson 등에 지원이 된다.)
- ubuntu 18.04 이상
- Nvidia-drivier
- docker
- nvidia-docker2
https://docs.nvidia.com/deeplearning/triton-inference-server/release-notes/index.html
Release Notes :: NVIDIA Deep Learning Triton Inference Server Documentation
The actual inference server is packaged in the Triton Inference Server container. This document provides information about how to set up and run the Triton inference server container, from the prerequisites to running the container. The release notes also
docs.nvidia.com
먼저, PC에 설치된 Ubuntu의 Host의 nvidia-driver 버전을 확인하고 지원하는 Docker 버전을 확인하자


최신버전을 쓰면 좋겠지만, 사정상 Driver 업데이트가 안될 수 있으므로 알맞은 버전을 설치하도록 하자 Driver Requirements를 만족하지 못하게 되면, CUDA관련 오류들이 나타날 수 있다.
docker pull 명령어를 통해서 해당버전의 docker image를 받으면 된다
Quickstart — NVIDIA Triton Inference Server
<!-- # Copyright (c) 2018-2023, NVIDIA CORPORATION. All rights reserved. # # Redistribution and use in source and binary forms, with or without # modification, are permitted provided that the following conditions # are met: # * Redistributions of source co
docs.nvidia.com
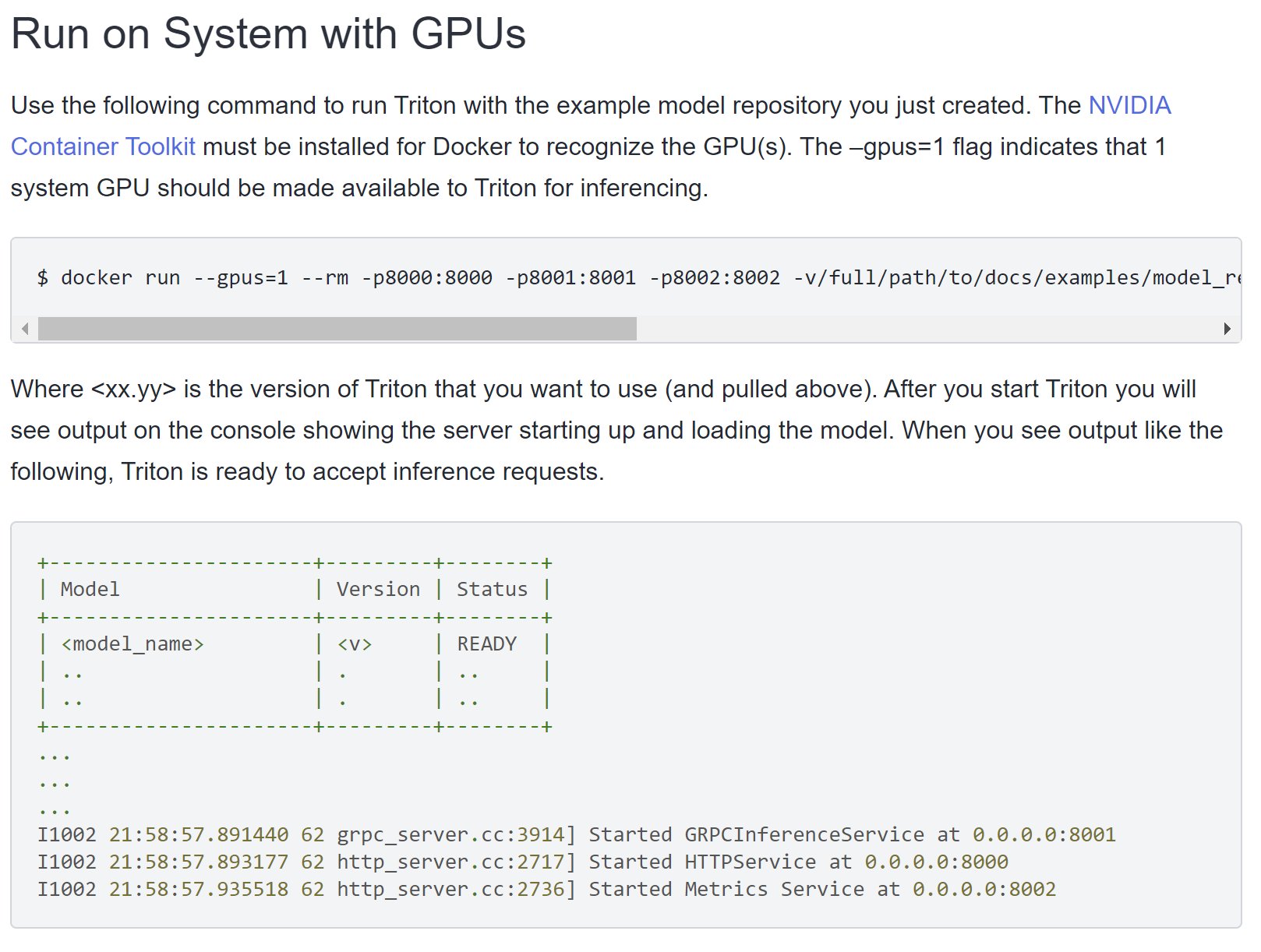
$ docker run --gpus=1\ ## gpu 번호
-p8000:8000 -p8001:8001-p8002:8002\ ## port -> grpc, https, metrics
-v/full/path/to/docs/examples/model_repository:/models # 볼륨
nvcr.io/nvidia/tritonserver:<xx.yy>-py3\ # image
tritonserver --model-repository=/models # 명령어
명령어 부분의 tritonserver의 여러 기능들이 있는데 이부분은 따로 정리하고자 한다. --mdoel-repository는 root기준에서 /models 폴더에 있는 모델 폴더들을 배포하겠다는 뜻이된다.
--gpus 명령어를 빼주면 cpu로 로드도 가능하다. (cpu가 과연 버틸까..?)
Health Check
curl -v localhost:8000/v2/health/ready결과
...
< HTTP/1.1 200 OK
< Content-Length: 0
< Content-Type: text/plain
해당 결과가 나온다면 성공적으로 서버가 동작하는 것이다.