AI 서비스를 운영하는데 있어 비용적 측면은 매우 중요한 사항이 아닐 수 없다.
AI의 성능은 성능적으로 매우 빠르게 증대되며, 그에 따라 VRAM과 전력소모와 같은
요구사항 스펙이 늘어날 수 밖에 없다.
이것을 상쇄시키기에 비싼 Nvidia Gpu를 많이 사용하고 싶지만, 그 비용은 Nvidia 주식가격(오늘 이 제일 쌉니다 ㅎㅎ) 만큼 비용이 많이 들것이다.
따라서 이 비용을 절감하기 위해서 효율적으로 서비스를 운영하기 위해 모델의 경량화는 필수일 것이다.
엔비디아에서는 이러한 Gpu를 사용하는 기기에서는 최적화 해주는 기능을 제공해주며, 이를 적극적으로 도입할 필요가 있다.

TF-TRT(TensorFlow)나 torch2trt(Pytorch) 등을 딥러닝 프레임워크에서 지원해 주지만
최신의 모델이나 복잡한 모델이면 호환성, 지원등의 문제 때문에 간혹 잘 되지 않는경우가 발생한다.
(TenSorrt의 제작자도 기존프레임워크 -> ONNX -> Tensorrt 의 형태로 변형하는게 가장 안전하다고 얘기한다.)
따라서 포스팅에서는 기존프레임워크 -> ONNX -> Tensorrt 형태로 변환하는 것을 다루고자 한다.
(추후 포스팅에서 기회되면 TF-TRT(TensorFlow)나 torch2trt(Pytorch)도 다뤄보고자 한다.
먼저. Tensorrt의 기본개념부터 확인해보자
Tensorrt 기본 개념
Network compression, Network optimization 그리고 GPU 최적화 기술들을 대상 Deep Learning 모델에 자동으로 적용하여, Binary * 엔진파일 형태로 저장된다. 그래서 확장자가 Engine 또는 Trt이다.
*(Binary Large Object의 약자로 하나의 객체로 나타내어 2진수로 저장)
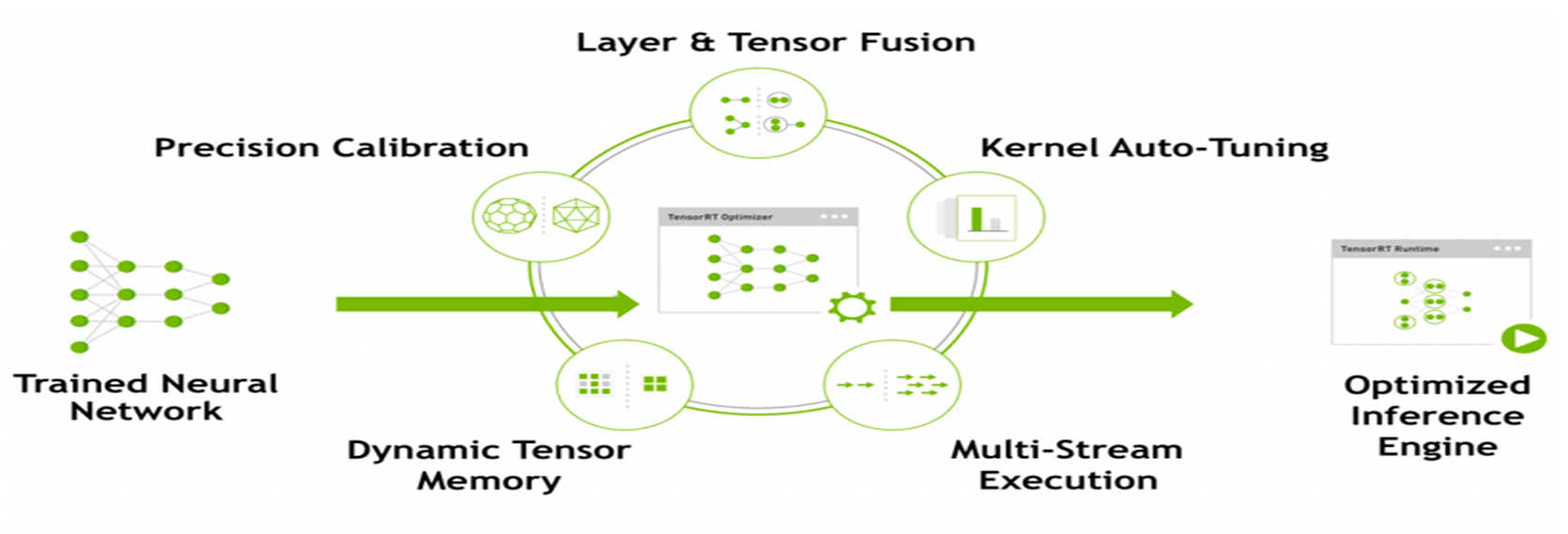
사용되는 기술들을 하나씩 보자
Layer Fusion & Tensor Fusion
여러단계의 Layer를 Fusion을 통해 단순화 시키고 Layer 갯수를 감소시켜 연산하여 속도향상시킨다.
예를 들어 3가지 물건을 사는데, 3번 따로 슈퍼마켓에 가는 것을 한번 슈퍼마켓에 가서 3개를 다 사는것으로 변환시킨다고 보면 된다.

Precision Calibration
딥러닝 프레임워크의 일반적인 FP32 타입의 데이터를 FP16 및 INT8의 데이터 타입으로 정밀도 조정 가능하다.
이부분이 Tensorrt의 핵심기술 이라고 생각되는데, 데이터의 표현범위를 낮춤으로써 사용되는 자원의 양을 획기적으로 줄이고 동작에 대한 속도도 매우 크게 증대시킨다.
단, 이렇게 되다보니 정확도 측면에서는 약간의 손실이 발생할 수 밖에 없다.

Kernel Auto-tuning
다양한 플랫폼과 아키텍쳐에 맞는 RunTime에 대한 data layer와 알고리즘 추천 즉, 디바이스 환경마다 자동으로 최적화 되어 셋팅 되는데 이부분 때문에 각 Tensorrt 엔진마다 서로 호환이 안되고 버전마다도 호환이 잘 안된다. 처음 배울 때, 셋팅하다가 키보드 샷건을 몇번을 때렸는지 모르겠다.

Dynamic Tensor Memory
최소화된 footprint 와 re-uses 메모리를 통해 tensor의 효율화를 가능하게 하는데, 메모리 re-use를 통해서 자원의 최적화를 도모하는거 같다.

Multi-stream execution
CUDA Stream 기술을 활용하여 여러개의 input Stream을 스케줄링 통해 최적의 병렬처리 구성이 가능하다.
이게 개쩌는게 batch로 병렬처리를 가능하게 해주어 각 input stream을 1:1로 처리하는게 아닌 n:1로 처리가 가능하여 대량의 input data를 효율적이게 Inferece 가능하게 해주고 자원 낭비를 막아준다.
예를 들어 cctv가 1대라면 자원적으로 크게 상관할 필요가 없겠지만, 100대의 cctv에서 데이터가 들어오면 어떻겠는가? 이걸 1:1로 매칭한다면 그에 따라 gpu갯수도 매우 많이 필요하겠지만, Tensorrt inference는 병렬처리가 가능하여, 이를 묶어서 한번에 inference가 가능하다(물론 느려지긴한다.)
이에 대한 부분은 deepstream 포스팅에서 자세히 다루도록 하겠다.

Tensorrt 사용방법
먼저 Tensorrt 릴리즈 노트를 확인해서 내 디바이스에서 호환되는 버전이 몇 버전인지 확인하자,
최신버전을 쓰는게 가장 좋겠지만, 프로젝트의 상황에 따라 이를 맞춰줄 수 있고 없고가 있을 것이다.
첫 단추부터 잘못 끼면 프로젝트 동안 머리가 아주 아플 수 있으니,
릴리즈 노트를 꼭 꼼꼼히 읽어서 지원여부를 확인하고 사용하자!
https://docs.nvidia.com/deeplearning/tensorrt/release-notes/index.html
Release Notes :: NVIDIA Deep Learning TensorRT Documentation
These are the TensorRT 8.5.2 Release Notes and are applicable to x86 Linux, Windows, JetPack, and PowerPC Linux users. This release incorporates Arm® based CPU cores for Server Base System Architecture (SBSA) users on Linux only. This release includes sev
docs.nvidia.com
설치방법은 총 3가지이다.
- 도커 컨테이너
- 리눅스 로컬에서 직접 설치
- python pip을 이용한 설치
이 세가지 중, 도커를 이용한 설치를 추천한다.
여러 버전을 독립적으로도 실험이 가능하니 안될 때마다 다른 버전 을 설치해서 해볼 수 있기 때문에
강추한다. (python pip 설치도 이미 컨테이너에 되있기 때문에 호환성 문제도 없다.)
(Tensorrt 컨테이너 사용법)
https://catalog.ngc.nvidia.com/orgs/nvidia/containers/tensorrt
(컨테이너 릴리즈 노트) -> 호환되는지 꼼꼼히 읽자
https://docs.nvidia.com/deeplearning/tensorrt/container-release-notes/index.html
TensorRT Container Release Notes
The TensorRT container is an easy to use container for TensorRT development. The container allows you to build, modify, and execute TensorRT samples. These release notes provide a list of key features, packaged software in the container, software enhanceme
docs.nvidia.com
모델은 기본적으로 구글의 Tensorflow나 페이스북의 Pytorch, 혹은 Keras 등으로 학습된 모델파일이 생성된다.
이를 일반적으로 경량화 하는 방법은 ONNX와 Tensorrt이다.
ONNX는 서로다른 딥러닝 프레임 워크들을 공유하기 위해 사용되는 포맷이라면
Tensorrt는 Nvidia GPU에 추론의 최적화를 할 수 있도록 하는 엔진이다.
Tensorrt를 사용하여 추론하려면 기존 딥러닝 프레임워크에서
ONNX 변환 후, Tensorrt로 변환이 필요하다.
요즘 최신모델들을 보면 기본적으로 제작자들이 TensorRT 변환에 대한 가이드를 대부분 제공하고 있으니, 그것을 따라하는 것도 좋다.
다음번에는 실제 사용되는 모델을 가지고 Tensorrt 변환을 시도해 보자