Mongo DB 특징
- 문서 모델이다.
• 속성의 값은 숫자, 문자열, 날짜와 같이 간단한 데이터 타입이나 배열, 또는 다른 문서가 될 수 있다.
• 문서의 구조가 다양하다. (=> json같은 형태이다.)
• 미리 정해진 스키마가 존재하지 않는다.
• 애플리케이션에서 저장 구조를 정한다.
• 구조가 빈번히 조정되는 초기단계에 매력적이다.
- 한 컬랙션(= 테이블이라 생각하면 이해 쉬움)에 64개까지 인덱스 생성 가능하다.
- 복제 환경 구성이 가능하고 자동 샤딩(RDB에서도 사용하는 클러스터 확장 방법)으로 분산 환경 구성이 가능하다.
• 수평적인 확장성이 좋다. 단, 무결성과 정합성을 보장하지 않기 때문에 장단점이 있다.
- 관계DB와 key-value 시스템의 장점을 결합하여 설계되었다.
• 관계DB의 강력한 질의어 + 단순하여 속도가 빠르고 확장성이 용이한 key-value 시스템 ## 웹 어플리케이션, 분석과 로깅 어플리케이션, 중간 정도의 캐시를 필요로 하는 어플리케이션의 저장시스템으로 좋다
find() 함수 활용
기본적으로, collection에 있는 모든 다큐먼트를 조회
db.COLLECTION-NAME.find()
를 입력하면 해당 컬렉션의 모든 document가 조회.
몇가지 조건을 추가.
위의 firstCollection을 바탕으로 하여, 성별(sex)가 남자(male)인 다큐먼트만 조회하려면?
find() 함수의 정의에서 살펴본 것처럼, query parameter에 조건을 추가
db.firstCollection.find({"sex":"male"})
전공이 운동(sport)인 다큐먼트의 이름(name)을 조회하려면
query와 projection 두개다 적절히 조건을 추가.
db.firstCollection.find({"major":"sport"},{"_id":false,"name":true})
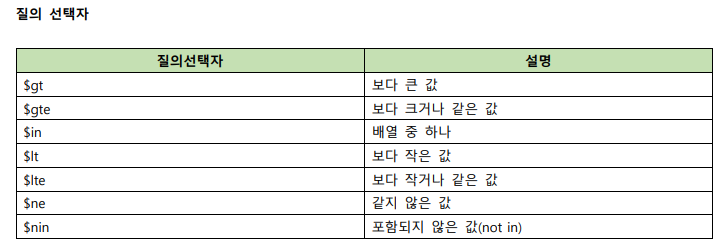
쿼리 연산자(Query operators)
쿼리연산자는 위에서 알아본 find() 함수와 함께 응용되어 다양한 기능을 할 수 있다.
쿼리 연산자는 프로그래밍 언어에서 사용되는 비교(Comparison), 논리(Logical)등과 같은 다양한 종류의 연산자가 있다.






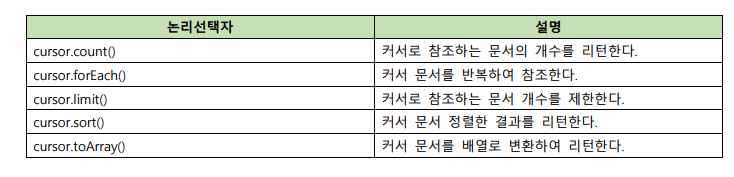
cursor 함수
find(), aggregate() 같이 값을 select하는 함수가 실행될 때는 찾는 진행 과정에 따라 cursor가 움직인다.
그 움직이는 커서에 따라 작동하는 함수가 또 다양하다.
보통 db.collection.find().count()같이 read질의어 뒤에 붙어서 작동한다.

1. 테이블 생성 및 삽입
- NoSQL은 테이블생성과정이 따로 없고 레코드 삽입과 동시에 테이블이 생성된다.
- db.컬렉션.insert()문을 통해 삽입이 이뤄진다.
NoSQL 데이터베이스로 작업하기
- 관계형 데이터는 주로 테이블 형식, 즉 관계가 있는 테이블 집합이라고 볼 수 있음
- 데이터 볼륨이 서버 용량을 초과하면 기존 관계형 데이터베이스 모델은 데이터를 단일 서버 대신 서버 클러스터에 저장
- 할 수 있는 수평 확장성을 지원하기가 쉽지 않기 때문에 문제가 발생함 데이터가 분산된 형태로 저장되더라도 마치 한 논리 데이터베이스인 것처럼 접근할 수 있으므로 데이터베이스 관리의 복잡성에 새로운 레이어가 추가됨
- 최근 NoSQL, 즉 비관계형 데이터베이스는 새로운 데이터베이스 모델의 도입과 빅데이터 분석 및 실시간 애플리케이션에서 나타나는 놀라운 성능으로 이전보다 훨씬 더 대중화됨
- 비관계형 데이터베이스는 높은 가용성, 확장성, 유연성, 고성능을 위해 설계함
NoSQL 데이터베이스로 작업하기
- 관계형 데이터베이스의 스토리지 모델과 비관계형 데이터베이스의 스토리지 모델 차이점을 주목해서 볼 필요가 있음
- 예를 들어 쇼핑 웹 사이트에서는 상품과 고객 의견을 저장하는 데 goods와 comments라는 테이블 2개가 있는 관계형 데이터베이스를 사용할 수 있음
- 상품 정보와 각 상품에 대한 의견은 모두 서로 다른 테이블에 각각 저장됨
- 다음은 이러한 테이블의 기본 구조를 보여줌

NoSQL 데이터베이스로 작업하기
- 각 의견에는 다음과 같이 제품을 가리키는 필드가 있음

MongoDB 작업하기
다음은 컬렉션 안에 있는 어떤 상품 내용을 JSON 형식(https://en.wikipedia.org/wiki/JSON)으로 출력한 것


- 관계형 데이터베이스는 여러 가지 스키마를 포함할 수 있음
- 각 스키마(또는 데이터베이스)는 많은 테이블로 구성될 수 있음
- 각 테이블은 많은 레코드를 포함할 수 있음
- 마찬가지로 MongoDB 인스턴스는 많은 데이터베이스를 호스팅할 수 있음
- 물론 각 데이터베이스는 여러 컬렉션을 포함 할 수 있음 각 컬렉션에는 많은 문서가 포함될 수 있음
- 관계형 데이터베이스의 가장 큰 차이점은 관계형 데이터베이스 테이블 안에 저장된 레코드는 구조가 모두 동일해야 함 - MongoDB 데이터베이스 컬렉션의 문서는 특정한 스키마가 없으며 중첩 구조를 가질 수 있을 만큼 유연하다는 것
MongoDB 작업하기
- 패키지가 설치되면 컬렉션, 데이터베이스, MongoDB 주소를 지정하여 MongoDB를 연결할 수 있음
- 제일 먼저 로컬 MongoDB 인스턴스에 연결함 당연히 products 컬렉션은 문서를 전혀 갖고 있지 않음
m <- mongo("products", "text", "mongodb://localhost:27017")
m

- 제품과 고객 의견을 등록하려고 m$insert()에 문자열 형태로 JSON 문서를 직접 입력할 수 있음
m$insert('
{
"code" : "A0000001",
"name" : "Product-A",
"type" : "Type-I",
"price" : 29.5,
"amount" : 500,
"comments" : [
{
"user" : "divid",
"score" : 8,
"text" : "This is a good product"
} ,
{ "user" : "jenny",
"score" : 5,
"text" : "Just so so"
}
]
}
')

또 다른 방식으로 구조가 같은 R의 리스트 객체를 사용할 수 있음
다음 코드는 list를 사용하여 두 번째 제품을 등록함
m$insert(list(
code = "A0000002",
name = "Product-B",
type = "Type-II",
price = 59.9,
amount = 200L,
comments = list(
list(user = "tom", socre = 6L, text = "Just fine"),
list(user = "mike", score = 9L, text = "great product!")
)
), auto_unbox = TRUE)

m$count()
그런 다음 컬렉션의 모든 문서를 불러오는 데 m$find() 함수를 사용할 수 있음
데이터 조작을 용이하게 할 수 있도록 자동으로 결과가 데이터 프레임으로 단순화됨
products <- m$find()
str(products)

컬렉션을 필터링하려고 m$find()에서 조건부 쿼리와 필드를 지정할 수 있음
먼저 code가 A0000001인 문서를 쿼리하고 name, price, amount 필드를 가져옴
m$find('{"code":"A0000001"}', '{ "_id":0, "name":1, "price":1, "amount":1}')

그런 다음 조건부 쿼리에서 $gte 연산자를 사용하여 price가 40 이상인 문서를 쿼리함
m$find('{"price":{"$gte":40}}', '{"_id":0, "name":1,"price":1,"amount":1}')

문서 필드뿐만 아니라 배열 필드 안에 있는 객체 필드도 쿼리에 사용할 수 있음
다음 코드는 고객 평가가 9점인 고객 의견이 있는 문서를 모두 검색함
m$find('{"comments.score":9}','{"_id":0, "code":1, "name":1}')
마찬가지로 다음 코드는 고객 평가가 6점 미만인 고객 의견이 있는 문서를 모두 검색함
마침표(.)를 사용한 표현법으로 하위 문서의 필드에 쉽게 접근하여 작업을 수행할 수도 있음
이것으로 중첩 구조를 매우 쉽게 다룰 수 있음
m$find('{"comments.score":{"$lt":6}}','{"_id":0, "code":1, "name":1}')

확인해 보니 처음에는 컬렉션에 문서가 없음 일부 데이터를 삽입하려고 간단한 데이터 프레임을 만들어 보자
students <- data.frame(
name = c("David","Jenny","Sara","John"), age = c(25,23,26,23),
major = c("Statistics", "Physics", "Coumuter Science", "Statistics"),
projects = c(2,1,3,1), stringsAsFactors = FALSE)
)
students
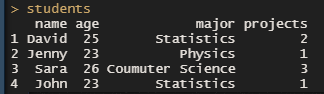
이 데이터 프레임의 행을 문서로 해당 컬렉션에 입력할 것

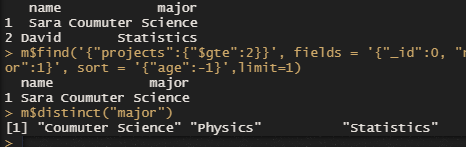
m$find('{"name":"Jenny"}')
m$find('{"projects":{"$gte":2}}')
m$find('{"projects":{"$gte":2}}', fields = '{"_id":0, "name":1, "major":1}')

m$find('{"projects":{"$gte":2}}', fields = '{"_id":0, "name":1, "major":1}', sort = '{"age":-1}',limit=1)
m$distinct("major")
m$distinct("major", '{"projects":{"$gte": 2}}')
- 인덱스 생성 및 제거하기 관계형 데이터베이스와 마찬가지로 MongoDB도 인덱스를 지원함
- 각 컬렉션에는 인덱스가 여러 개 있을 수 있음 인덱스 필드는 빠르게 조회하려고 메모리에 캐시됨 인덱스를 올바르게 - 작성하면 문서 조회를 매우 효율적으로 수행할 수 있음
- mongolite를 사용하여 MongoDB에서 쉽게 인덱스를 만들 수 있음 데이터를 컬렉션으로 가져오기 전 혹은 후에 수행할 수 있음
- 이미 문서를 수십억 개 가져왔다면 인덱스를 생성하는 데 시간이 오래 걸릴 것 컬렉션에 문서를 넣기 전에 수많은 인덱스를 만들어야 한다면 문서를 삽입하는 성능이 저하될 수 있음
m$update('{"name":"Jenny"}', '{"$set":{"age":24}}')
m$find()
m$index('{"name":1}')
m$find('{"name":"Sara"}')
m$find('{"name":"Jane"}')

set.seed(123)
m <- mongo("simulation", "test")
sim_data <- expand.grid(
type=c("A","B","C","D","E"), category = c("P-1","P-2","P-3"),
group = 1:20000, stringsAsFactors = FALSE)
m$insert(sim_data)
system.time(recs2 <- m$find('{"score1" : { "$gte":20} }'))
# 첫 번째 테스트는 인덱스 없이 문서를 쿼리하는 데 시간이 얼마나 걸리는지 찾는 것
system.time(rec <- m$find('{"type" :"C", "category":"P-3", "group":87}'))
rec
# 두 번째 테스트는 공통 조건이 있는 문서를 찾는 성능에 관한 것
system.time({
recs <- m$find('{"type":{"$in":["B","D"]},
"category":{"$in":["P-1","P-2"]},
"group":{"$gte":25, "$lte":75}}')
})
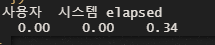
# 여기 students 컬렉션에 대한 인덱스를 만듦
m$index('{"name":1}')

#인덱스가 있는 필드로 문서를 검색한다면 엄청나게 빠른 성능을 얻게 됨
m$find('{"name":"Sara"}')

#조건을 만족하는 문서가 없다면 빈 데이터 프레임 객체를 돌려받음
m$find('{"name": "Jane"}')

#MongoDB의 또 다른 중요한 기능은 집계 파이프라인임
#데이터를 집계할 때 일련의 집계 연산을 입력하여 MongoDB 인스턴스가 이것을
#스케줄하도록 함
#예를 들어 다음 코드들은 데이터를 타입별로 그룹화함
#각 그룹은 필드 개수, 평균 점수, 최소 점수, 최대 점수를 갖음
#각 코드의 출력이 길 수 있기 때문에 여기에 모두 출력하지는 않을 것
#코드를 직접 실행하여 그 결과를 확인할 수 있음
m$aggregate('[
{"$group": {
"_id": "$type",
"count" : {"$sum":1},
"avg_score" : {"$avg":"$score1"},
"min_text" : {"$min":"$test1"},
"max_test" : {"$max": "$test1"}
}
}
]')
m$aggregate('[
{"$group": {
"_id": {"type":"$type", "category":"$category"}
"count" : {"$sum":1},
"avg_score" : {"$avg":"$score1"},
"min_text" : {"$min":"$test1"},
"max_test" : {"$max": "$test1"}
}
}
]')
#MapReduce의 첫 번째 단계는 map임
#이 단계에서 모든 값은 키-값 쌍에 매핑됨
#reduce 단계에서는 키-값 쌍을 집계함
#앞 예제에서 각 bin에 포함된 레코드 개수를 간단히 계산함
bins <- m$mapreduce(
map = 'function() {
emit(Math.floor(this.score1 / 2.5) * 2.5, 1);
}',
reduce = 'function(id, counts) {
return Array.sum(counts);}'
)
bins
# 이렇게 얻은 bins에서 막대 그래프를 그릴 수 있음
with(bins, barplot(value / sum(value), names.arg="_id",
main = "점수 히스토그램", xlab="socre1", ylab = "Percentage"))

'경기도 인공지능 개발 과정 > SQL' 카테고리의 다른 글
| [SQL] 데이터 그룹 (0) | 2022.08.12 |
|---|---|
| SQL SQLite 사용 (0) | 2022.04.29 |
| SQL 활용 (0) | 2022.04.22 |
| SQL 기초 (0) | 2022.04.22 |
| SQL mysql 실습 셋팅 (0) | 2022.04.20 |