## '한국복지패널데이터' 분석 준비하기
#### 한국복지패널데이터
# - 한국보건사회연구원 발간
# - 가구의 경제활동을 연구해 정책 지원에 반영할 목적
# - 2006~2015년까지 전국에서 7000여 가구를 선정해 매년 추적 조사
# - 경제활동, 생활실태, 복지욕구 등 수천 개 변수에 대한 정보로 구성
###############################
### 데이터 분석 준비하기
# 1. 패키지 준비하기
# foreign : SPSS 파일 다루기
# dplyr : 데이터 전처리
# ggplot2 : 데이터 시각화
# readxl : 엑셀 파일 다루기
# 2. 데이터 준비하기 (./data_files/Koweps_hpc10_2015_beta1.sav)
# 2-1. 원시 데이터 불러오기
raw_welfare <- read.spss("./data_files/Koweps_hpc10_2015_beta1.sav", to.data.frame = T)
# 2-2. 작업을 위한 복사본
welfare <- raw_welfare
# 3. 데이터 검토하기
head(welfare)
# 4. 분석하기 쉬운 변수명으로 변경 : rename()
welfare <- rename(welfare,
sex = h10_g3,
birth = h10_g4,
marriage = h10_g10,
religion = h10_g11,
income = p1002_8aq1,
code_job = h10_eco9,
code_region = h10_reg7
)
###############################
###############################
# 일반적인 데이터 분석 절차
# 1. 변수 검토 및 전처리 : 이상치 / 결측치
# 2. 변수간 관계 분석 : 요약을 통한 간단한 사각화
###############################
###############################
# 첫 번째 : 성별에 따라 급여가 다를까??
## 성별 변수(sex) 검토 및 전처리 ##
# 1. 변수 검토 : 변수의 데이터 타입(class()) / 각 범주에 대한 빈도 (table())
class(welfare$sex)
table(welfare$sex)

# 데이터 전처리 : 1 => "male" / 2 => "female"
welfare$sex <- if_else(welfare$sex == 1, "male", "female")
# 2. 변수간 관계 분석 : 요약을 통한 간단한 시각화
table(welfare$sex)
qplot(welfare$sex)
## 급여(월급) 변수(income) 검토 및 전처리 ##
# 1. 변수 검토 :
class(welfare$income)
summary(welfare$income)

# 데이터 전처리 : 결측치 => 0, 9999 값
# 이상치를 결측치로 변경
welfare$income <- if_else(welfare$income %in% c(0, 9999), NA, welfare$income)
# 결측치 확인
table(is.na(welfare$income))

# 2. 변수간 관계 분석
qplot(welfare$income) + xlim(0, 1000)

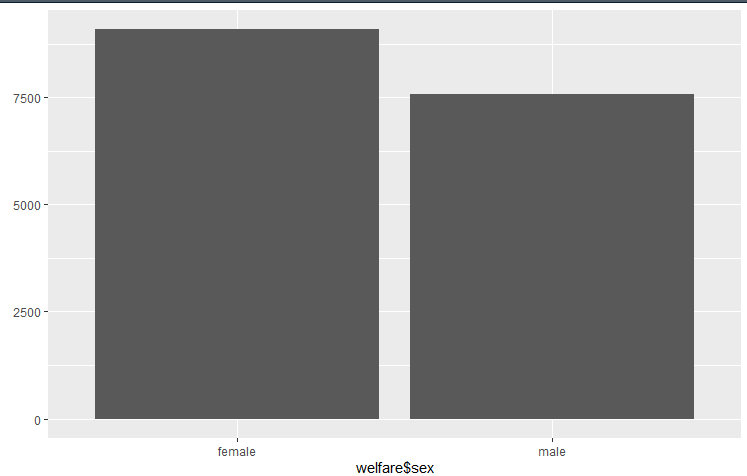
## 성별에 따른 급여 차이 분석
sex_income <- welfare %>% filter(!is.na(income)) %>% group_by(sex) %>% summarise(mean_income = mean(income))
## 결과를 이용한 간단한 시각화
ggplot(data=sex_income, aes(x=sex, y=mean_income)) + geom_col()

###############################
###############################
# 두 번째. 몇 살에 급여를 가장 많이 받을까??
# 1. 나이 변수 검토
class(welfare$birth)
summary(welfare$birth)

table(is.na(welfare$birth))
# 2. 데이터 전처리 : 태어난 연도(birth)를 이용하여 나이변수(age)를 추가
welfare$age <- 2021 - welfare$birth +1
summary(welfare$age)

# 3. 결과를 이용한 간단한 시각화
qplot(welfare$age)

# 나이 기준 그룹화 / 월급 평균
age_income <- welfare %>% filter(!is.na(income)) %>% group_by(age) %>% summarise(mean_income = mean(income))
# 분석 결과 시각화
ggplot(data = age_income, aes(x=age, y=mean_income)) + geom_line()

###############################
###############################
# 세 번째 연령대에 따른 급여 (초년:30 / 중년:30~59 / 노년:60)
# 1. 연령대 변수 생성 30미만 TRUE FLASE 30<age<=59 TRUE FALSE
welfare <- welfare %>% mutate(ageg = ifelse(age < 30, "young", ifelse(age <=59, "middle", "old")))
table(welfare$ageg)

qplot(welfare$ageg)
# 2. 연령대에 따른 평균 급여 차이 분석
ageg_income <- welfare %>% filter(!is.na(income)) %>% group_by(ageg) %>% summarise(mean_income = mean(income))
# 분석 결과를 이용한 간단한 시각화
ggplot(data = ageg_income, aes(x = ageg, y= mean_income)) + geom_col()

# ggplot() x 축 부분은 알파벳 순서로 출력
# 출력 순서를 변경할 경우 scale_x_discrete()를 이용하여 재정의 할 수 있다
# scale_x_discrete(limits = c(정렬 순서))
ggplot(data = ageg_income, aes(x = ageg, y= mean_income)) + geom_col() + scale_x_discrete(limits = c("young", "middle", "old"))
###############################
###############################
# 연령대, 성별에 따른 급여 차이
# 1. 평균
sex_income <- welfare %>% filter(!is.na(income)) %>% group_by(ageg, sex) %>% summarise(mean_income = mean(income))
# `summarise()` has grouped output by 'ageg'. You can override using the `.groups` argument.
# => 출력 결과를 연령별로 분류한 결과 , 'group 를 이용하여 재정의가 가능합니다
# 2. 분석 결과를 이용한 간단한 사각화
ggplot(data = sex_income, aes(x = ageg, y= mean_income, fill=sex)) +
geom_col() +
scale_x_discrete(limits = c("young", "middle", "old"))
# fill=sex : 성별에 따라 다른 색으로 표현하고자 할 때
# 성별에 따른 막대 그래프 분리 : geom_col(position="dodge")
ggplot(data = sex_income, aes(x = ageg, y= mean_income, fill=sex)) +
geom_col(position = "dodge") +
scale_x_discrete(limits = c("young", "middle", "old"))

###############################
###############################
# 나이, 성별 급여 차이 분석
# 1. 평균
sex_age <- welfare %>% filter(!is.na(income)) %>% group_by(age, sex) %>% summarise(mean_income = mean(income))
# 2. 분석 결과를 이용한 간단한 시각화
ggplot(data = sex_age, aes(x = age, y = mean_income, col=sex)) + geom_line()

###############################
###############################
# 직업별 급여 차이
# 1. 직업 변수(code_job) 검토 및 전처리
class(welfare$code_job)
table(welfare$code_job)
# 직업 코드를 직업명으로 변경 : Koweps_Codebook.xlsx 파일을 이용
list_job <- read_excel("./data_files/Koweps_Codebook.xlsx",col_names = T, sheet = 2)
dim(list_job)
# welfare 와 list_job 를 가로 결합 : left_join()
welfare <- left_join(welfare, list_job, id = "code_job")
welfare %>% filter(!is.na(code_job)) %>% select(code_job, job) %>% head(10)
# 2. 직업별 급여 분석 : 평균
job_income <- welfare %>% filter(!is.na(job) & !is.na(income)) %>% group_by(job) %>% summarise(mean_income = mean(income))
head(job_income)

# 3. 데이터를 내림 차순으로 상위 10 개 데이터
top10 <- job_income %>% arrange(desc(mean_income)) %>% head(10)
# 4. 상위 10개 직업에 대한 시각화
ggplot(data = top10, aes(x = job, y = mean_income)) + geom_col()
ggplot(data = top10, aes(x = job, y = mean_income)) + geom_col() + coord_flip()
ggplot(data = top10, aes(x = reorder(job, mean_income), y = mean_income)) + geom_col() + coord_flip()

# 5. 하위 10개 직업에 대한 시각화
bottom10 <- job_income %>% arrange(mean_income) %>% head(10)
ggplot(data = bottom10, aes(x = reorder(job, mean_income), y = mean_income)) + geom_col() + coord_flip()
###############################
###############################
# 성별 직업 빈도
# 1. 남성 직업 빈도 상위 10 개
job_male <- welfare %>% filter(!is.na(job) & sex == "male") %>% group_by(job) %>%
summarise(n = n()) %>% arrange(desc(n)) %>% head(10)
# 2. 여성 직업 빈도 상위 10 개
job_female <- welfare %>% filter(!is.na(job) & sex == "female") %>% group_by(job) %>%
summarise(n = n()) %>% arrange(desc(n)) %>% head(10)
# 시각화
ggplot(data = job_male, aes(x = reorder(job, n), y = n)) + geom_col() + coord_flip()

ggplot(data = job_female, aes(x = reorder(job, n), y = n)) + geom_col() + coord_flip()
###############################
###############################
# 종교 유무에 따른 이혼율
# 1. 종교 변수(code_religion) 검토 및 전처리
class(welfare$religion)
table(welfare$religion)
welfare$religion <- ifelse(welfare$religion == 1, "yes", "no")
table(welfare$religion)
qplot(welfare$religion)
# 2. 혼인상태 변수(marriage) 검토 및 전처리
class(welfare$marriage)
table(welfare$marriage)
welfare$group_marriage <- ifelse(welfare$marriage == 1, "marriage", ifelse(welfare$marriage == 3, "divorce", NA))
table(welfare$group_marriage)
table(is.na(welfare$group_marriage))
qplot(welfare$group_marriage)
# 3. 종교 유무에 따른 이혼율 : round()
# 3-1. 종교 유무, 결혼 상태별로 분리 => 빈도수 => 종교 유무 그룹의 잔체 빈도로 나누어 비율을 구하기...
# 3-2. 비율은 소숫점 이하 자리수가 길어 질 수 있기 때문에 round()를 이용하여 소숫점 첫 째자리 까지만..
religion_marriage <- welfare %>% filter(!is.na(group_marriage)) %>%
group_by(religion, group_marriage) %>%
summarise(n = n()) %>%
mutate(tot_group = sum(n)) %>%
mutate(pct = round(n/tot_group*100, 1))
religion_marriage2 <- welfare %>% filter(!is.na(group_marriage)) %>%
count(religion, group_marriage) %>%
group_by(religion) %>%
mutate(pct = round(n/sum(n)*100, 1))
# 4. 이혼에 해당하는 값만 추출
divorce <- religion_marriage %>% filter(group_marriage == "divorce") %>%
select(religion, pct)
# 분석 결과를 이용한 시각화
ggplot(data = divorce, aes(x = religion, y = pct)) + geom_col()
##########################################
##########################################
# 연령대 및 종교 유무에 따른 이혼율 분석
# 1.연령대 별 이혼율 표
ageg_marriage <- welfare %>% filter(!is.na(group_marriage)) %>%
group_by(ageg, group_marriage) %>%
summarise(n = n()) %>%
mutate(tot_group = sum(n)) %>%
mutate(pct = round(n/tot_group*100, 1))
# 2. 시각화
ageg_divorce <- ageg_marriage %>%
filter(ageg != "ypung" & group_marriage == "divorce") %>%
select(ageg, pct)
ggplot(data = ageg_divorce, aes(x = ageg, y = pct)) + geom_col()
# 3. 연령대, 종교 유무에 따른 상태별 표
ageg_religion_marriage <- welfare %>%
filter(!is.na(group_marriage) & ageg != "young") %>%
group_by(ageg, religion, group_marriage) %>%
summarise(n = n()) %>%
mutate(tot_group = sum(n)) %>%
mutate(pct = round(n/tot_group*100), 1)
# 4. 이혼율 표
df_divorce <- ageg_religion_marriage %>%
filter(group_marriage == "divorce") %>%
select(ageg, religion, pct)
# 5. 시각화
ggplot(data = df_divorce, aes(x = ageg, y = pct, fill = religion)) + geom_col()
ggplot(data = df_divorce, aes(x = ageg, y = pct, fill = religion)) + geom_col(position = "dodge")
########################################
# 지역별 연령대 비율 :
# R을 이용하여 데이터를 분석하는 일반적인 절차
# 1. 변수 검토 및 전처리
# 2. 변수간 관계분석
# 노년층이 살고 있는 지역
# 1. 지역변수(code_region) 검토
class(welfare$code_region)
table(welfare$code_region)
# 2. 지역변수 데이터 전처리 : 1~7 의 숫자를 지역명으로 변경
# welfare$code_region 와 매핑(합하기)을 위한 데이터 프레임 생성
list_region <- data.frame(code_region = c(1:7),
region = c("서울", "수도권(인천/경기)", "부산/경남/울산", "대구/경북", "대전/충남", "강원/충북", "광주/전남/전북/제주도")
)
# 지역명 변수를 추가
welfare <- left_join(welfare, list_region, id = "code_regoin")
welfare %>% select(code_region, region) %>% head(10)
# 3. 지역별 연령대 비율표 : 지역 및 연령대별로 나눈 후, 빈도 구하기. 각 지역에 대한 전체 빈도 구히기
region_ageg <- welfare %>% group_by(region, ageg) %>%
summarise(n = n()) %>%
mutate(tot_group = sum(n)) %>%
mutate(pct = round(n/tot_group*100, 2))
head(region_ageg)
# 4. 분석결과를 이용한 시각화
ggplot(data = region_ageg, aes(x = region, y = pct, fill = ageg)) + geom_col()
ggplot(data = region_ageg, aes(x = region, y = pct, fill = ageg)) + geom_col() + coord_flip()
# 5. 노년층 비율이 높은 순으로 정렬
list_order_old <- region_ageg %>% filter(ageg == "old") %>% arrange(pct)
# 6. 지역명 순서 저장 변수 : 시각화 작업에서 사용될 변수
order <- list_order_old$region
ggplot(data = region_ageg, aes(x = region, y = pct, fill = ageg)) +
geom_col() +
coord_flip() +
scale_x_discrete(limits = order)
# 막대 색상 순서 변경 : fill에 지정할 변수의 범주(level)의 순서를 지정
# 연령대(ageg) 의 데이터 형태가 문자. => 1. ageg => factor => 2. level 을 설정
class(region_ageg$ageg)
levels(region_ageg$ageg)
region_ageg$ageg <- factor(region_ageg$ageg,
level = c("old", "middle", "young")
)
ggplot(data = region_ageg, aes(x = region, y = pct, fill = ageg)) +
geom_col() +
coord_flip() +
scale_x_discrete(limits = order)
########################################
'경기도 인공지능 개발 과정 > 과제' 카테고리의 다른 글
| Python 초보자를 위한 파이썬 300제 (21 ~ 100) (0) | 2022.05.18 |
|---|---|
| Python 초보자를 위한 파이썬 300제 (1 ~ 20) (0) | 2022.05.17 |
| SQL 과제 - 팀별 SQL퀴즈 풀기 (0) | 2022.04.23 |
| R 1차 04/12 과제 -2 (0) | 2022.04.13 |
| R 1차 04/12 과제 -1 (0) | 2022.04.12 |