초기값 설정
초기값을 잘못 설정한다면 sigmoid를 통하고 하면서 w값을 가야되는데, 초기값에서 크게 벗어나지 못하는 문제가 발생
초기값을 잘 설정하는게 중요함 모델을 여러번 학습하다 보니, 학습된 모델이 다르게 나오게 된다.

Weight Initializtion은 새로운 방법으로 여러 연구가 있었음

초기화 설정 문제 해결을 위한 Naïve한 방법
-표준 정규분포를 이용해 초기화
-표준편차를 0.01로 하는 정규분포로 초기화
Nural Net 굉장히 크고 노드가 많다면 하나의 레이어에 잇는 100개의 Normal한 Naive한 방법인 평균0 표준편차 1인 정규화 방법을 쓰면, 나중에는 양쪽 끝으로 몰리는 현상이 발생함 이러한 표준편차를 줄여보는 시도를 함

Xavier 초기화 방법 + Sigmoid 함수
표준 정규 분포를 입력 개수의 제곱근으로 나누어 줌 Sigmoid와 같은 S자 함수의 경우 출력 값들이 정규 분포 형태를 가져야 안정적으로 학습 가능

Xavier 초기화 방법 + ReLU 함수
ReLU 함수에는 Xavier 초기화가 부적합 레이어를 거쳐갈수록 값이 0에 수렴
Xavier 초기화 방법과 + Relu를 사용했을때에도 레이어 거쳐갈수록 0에 수렴하되는데 Variance를 곱해주면서 activation이랑 관련이있음, sigmoid와 xavier 초기화 방법이 효율적

He 초기화 방법
표준 정규 분포를 입력 개수 절반의 제곱근으로 나누어 줌 ReLU 함수와 He 초기화 방법을 사용했을 경우의 그래프는 위와 같음 10층 레이어에서도 평균과 표준편차가 0 으로 수렴하지 않음
최근에는 He 초기화를 주로 사용
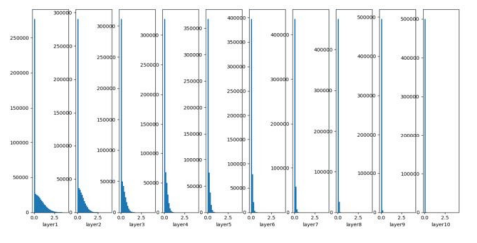

Naive한 가중치 초기화 방법 구현
가중치 초기화 문제는 활성화 함수의 입력값이 너무 커지거나 작아지지 않게 만들어주려는 것이 핵심
초기화 설정 문제 해결을 위한 Naive한 방법으론 평균이 0, 표준 편차가 1인 표준 정규 분포를 이용해 초기화하는 방법과 평균이 0, 표준 편차가 0.01인 정규분포로 초기화하는 방법
이번 실습에서는 각 방법으로 가중치를 초기화 해보고, 각 경우에 활성화 결괏값들의 분포가 어떻게 변화하는지 확인해봅시다. 실습을 마치고 나면 왜 Naive한 방식으로 가중치를 초기화 해서는 안되는지 알 수 있음
import numpy as np
from visual import *
np.random.seed(100)
def sigmoid(x):
result = 1 / (1 + np.exp(-x))
return result
def main():
x_1 = np.random.randn(1000, 100)
x_2 = np.random.randn(1000, 100)
node_num = 100
hidden_layer_size = 5
activations_1 = {}
activations_2 = {}
for i in range(hidden_layer_size):
if i != 0:
x_1 = activations_1[i-1]
x_2 = activations_2[i-1]
w_1 = np.random.randn(100, 100)
w_2 = np.random.randn(100, 100) * 0.01
a_1 = np.dot(x_1, w_1)
a_2 = np.dot(x_2, w_2)
z_1 = sigmoid(a_1)
z_2 = sigmoid(a_2)
activations_1[i] = z_1
activations_2[i] = z_2
Visual(activations_1,activations_2)
return activations_1, activations_2
if __name__ == "__main__":
main()
Xavier 초기화 방법 구현
가중치 초기화의 문제를 해결하기 위해 나온 방법 중 하나인 Xavier 초기화 방법은 현재 일반적인 딥러닝 프레임워크들이 표준적으로 이용
Xavier 초기화 방법은 앞 레이어의 노드가 n개일 때 표준 편차가 1/n1 / \sqrt{n}인 분포를 사용하는 것입니다. 즉 표준 정규 분포를 입력 개수의 제곱근으로 나눔.
따라서 Xavier 초기화 방법을 사용하면 앞 레이어의 노드가 많을수록 다음 레이어의 노드의 초깃값으로 사용하는 가중치가 좁게 퍼짐
import numpy as np
from visual import *
np.random.seed(100)
def sigmoid(x):
result = 1 / (1 + np.exp(-x))
return result
def relu(x):
result = np.maximum(0,x)
return result
'''
sigmoid와 relu를 통과할 값인 'a_sig', 'a_relu'를 정의
'''
def main():
x_sig = np.random.randn(1000,100)
x_relu = np.random.randn(1000,100)
node_num = 100
hidden_layer_size = 5
activations_sig = {}
activations_relu = {}
for i in range(hidden_layer_size):
if i != 0:
x_sig = activations_sig[i-1]
x_relu = activations_relu[i-1]
w_sig = np.random.randn(100,100) * 1 / np.sqrt(node_num)
w_relu = np.random.randn(100,100) * 1 / np.sqrt(node_num)
a_sig = np.dot(x_sig, w_sig)
a_relu = np.dot(x_sig, w_sig)
z_sig = sigmoid(a_sig)
z_relu = relu(a_relu)
activations_sig[i] = z_sig
activations_relu[i] = z_relu
Visual(activations_sig, activations_relu)
return activations_sig, activations_relu
if __name__ == "__main__":
main()
He 초기화 방법
He 초기화 방법은 활성화 함수로 ReLU를 쓸 때 활성화 결괏값들이 한쪽으로 치우치는 문제를 해결하기 위해 나온 방법
He 초기화 방법은 앞 레이어의 노드가 n개일 때 표준 편차가 2/n\sqrt{2} / \sqrt{n}인 분포를 사용하는 것입니다. 즉 표준 정규 분포를 입력 개수 절반의 제곱근으로 나누어줌
Xavier 초기화 방법은 표준 편차가 1/n1 / \sqrt{n}이라고 하였습니다. ReLU는 음의 영역에 대한 함숫값이 0이라서 더 넓게 분포시키기 위해 2\sqrt{2}배의 계수가 필요하
import numpy as np
from visual import *
np.random.seed(100)
def relu(x):
result = np.maximum(0,x)
return result
'''
relu를 통과할 값인 'a_relu'를 정의
'''
def main():
x_relu = np.random.randn(1000, 100)
node_num = 100
hidden_layer_size = 5
activations_relu = {}
for i in range(hidden_layer_size):
if i != 0:
x_relu = activations_relu[i-1]
w_relu = np.random.randn(100, 100) * np.sqrt(2/node_num)
a_relu = np.dot(x_relu, w_relu)
z_relu = relu(a_relu)
activations_relu[i] = z_relu
Visual(activations_relu)
return activations_relu
if __name__ == "__main__":
main()
과적합 방지 기법
- 정규화(Regularization)
- 드롭아웃
- 배치 정규화(Batch Normalization)
정규화
모델이 복잡해질수록 parameter들은 많아지고, 절댓값이 커지는 경향이 발생함 기존 손실함수에 규제항을 더해 최적값 찾기 가능
가령 레이어가 20개고 노드가 10개 면 weight 2000개 있는데, summation overfitting 의 절대값이 얼마나 큰지,
어떤 weight 값이 0이라면 그 모델이 중요하지 않다고 판단하고 이를 배제함
0으로 가게 만들어서 상수를 만드는 것처럼 w22를 0으로 만들거나 실질적으로 overffitnig을 막을 수 있음
L1 정규화(Lasso Regularization)
가중치의 절대값의 합을 규제항 loss를 weight값을 패널티를 주어 절대값을줄이는방식
가중치의 절댓값의 합을 규제 항으로 정의 작은 가중치들이 거의 0으로 수렴하여 몇개의 중요한 가중치들만 남음
L2 정규화(Ridge Regularization)
가중치의 제곱의 합을 규제항으로 정의 L1 정규화에 비하여 0으로 수렴하는 가중치가 적음큰 값을 가진 가중치를 더욱 제약하는 효과
w제곱을 사용하여 합을 본다. L1 에 비해 L2가 실제 0이 되는경우가 많음 서로 다른 방법의 정규화 임
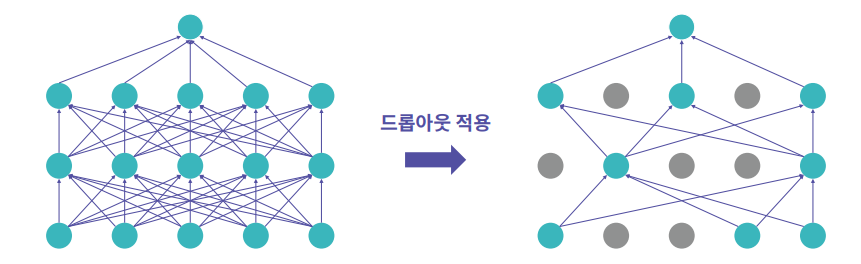
드롭아웃(DropOut)
각 layer마다 일정 비율의 뉴런을 임의로 drop시켜 나머지 뉴런들만 학습하는 방법임 드롭아웃을 적용하면 학습되는 노드와 가중치들이 매번 달라짐 다른 정규화 기법들과 상호 보완적으로 사용 가능 drop된 뉴런은 backpropagation 때 신호를 차단함 Test 때는 모든 뉴런에 신호를 전달
배치 정규화
머신러닝에서 feature를 생각하면 0에서 1이고 -3 에서 1이고 할 때, 값의 범위가 다르다면 잘 학습이 되지 않음
따라서 mean 0 var1로 옮겨서 줄여주는 방법등을 batch에서 사용하게 됨
매 Layer마다 정규화를 진행하므로 가중치 초기값에 크게 의존하지 않음(초기화 중요도 감소) 과적합 억제(Dropout, L1,L2 정규화 필요성 감소)

과적합 구현
과적합(Overfitting)은 모델이 학습 데이터에만 너무 치중되어 학습 데이터에 대한 예측 성능은 좋으나 테스트 데이터에 대한 예측 성능이 떨어지는 경우임
모델이 과적합되면 일반화되지 않은 모델
import numpy as np
import tensorflow as tf
from visual import *
import logging, os
logging.disable(logging.WARNING)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
# 데이터를 전처리하는 함수
def sequences_shaping(sequences, dimension):
results = np.zeros((len(sequences), dimension))
for i, word_indices in enumerate(sequences):
results[i, word_indices] = 1.0
return results
'''
1. 과적합 될 모델과 비교하기 위해 기본 모델 생성
'''
def Basic(word_num):
basic_model = tf.keras.Sequential([
tf.keras.layers.Dense(256, activation = 'relu', input_shape=(word_num,)),
tf.keras.layers.Dense(128, activation = 'relu'),
tf.keras.layers.Dense(1, activation= 'sigmoid')])
return basic_model
'''
2. 기본 모델의 레이어 수와 노드 수를 자유롭게 늘려서 모델을 생성
'''
def Overfitting(word_num):
overfit_model = tf.keras.Sequential([
tf.keras.layers.Dense(1024, activation = 'relu', input_shape=(word_num,)),
tf.keras.layers.Dense(512, activation = 'relu'),
tf.keras.layers.Dense(512, activation = 'relu'),
tf.keras.layers.Dense(512, activation = 'relu'),
tf.keras.layers.Dense(1, activation= 'sigmoid')])
return overfit_model
'''
3. 두 개의 모델을 불러온 후 학습시키고 테스트 데이터에 대해 평가
'''
def main():
word_num = 100
data_num = 25000
# Keras에 내장되어 있는 imdb 데이터 세트를 불러오고 전처리
(train_data, train_labels), (test_data, test_labels) = tf.keras.datasets.imdb.load_data(num_words = word_num)
train_data = sequences_shaping(train_data, dimension = word_num)
test_data = sequences_shaping(test_data, dimension = word_num)
basic_model = Basic(word_num) # 기본 모델
overfit_model = Overfitting(word_num) # 과적합시킬 모델
basic_model.compile(loss = "binary_crossentropy", optimizer="adam", metrics=["accuracy","binary_crossentropy"])
overfit_model.compile(loss = "binary_crossentropy", optimizer="adam", metrics=["accuracy","binary_crossentropy"])
basic_model.summary()
overfit_model.summary()
basic_history = basic_model.fit(train_data,train_labels, epochs=20, batch_size=500, validation_data = (test_data, test_labels), verbose=0)
print('\n')
overfit_history = overfit_model.fit(train_data,train_labels, epochs=300, batch_size=500, validation_data = (test_data, test_labels), verbose=1)
scores_basic = basic_model.evaluate(test_data, test_labels, verbose=0)
scores_overfit = overfit_model.evaluate(test_data, test_labels, verbose=0)
print('\nscores_basic: ', scores_basic[-1])
print('scores_overfit: ', scores_overfit[-1])
Visualize([('Basic', basic_history),('Overfitting', overfit_history)])
return basic_history, overfit_history
if __name__ == "__main__":
main()
L1, L2 정규화(Regularization) 기법
L1 정규화는 가중치(weight)의 절댓값에 비례하는 손실(loss)이 기존 손실 함수(loss function)에 추가되는 형태

L1 정규화는 모델 내의 일부 가중치를 0으로 만들어 의미있는 가중치만 남도록 만들어줌 이를 통해 모델을 일반화시킬 수 있음 다른 말로 Sparse Model을 만든다라고도 함
L2 정규화는 가중치의 제곱에 비례하는 손실이 기존 손실 함수에 추가되는 형태

L2 정규화는 학습이 진행될 때 가중치의 값이 0에 가까워지도록 만들어줌 가중치를 0으로 만들어주는 L1 정규화와는 차이가 있음 이를 통해 특정 가중치에 치중되지 않도록 가중치 값을 조율하게 되며 가중치 감소 (Weight Decay)라고도 함
import numpy as np
import tensorflow as tf
from visual import *
import logging, os
logging.disable(logging.WARNING)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
# 데이터를 전처리하는 함수
def sequences_shaping(sequences, dimension):
results = np.zeros((len(sequences), dimension))
for i, word_indices in enumerate(sequences):
results[i, word_indices] = 1.0
return results
'''
1. L1, L2 정규화를 적용한 모델과 비교하기 위한
하나의 기본 모델을 자유롭게 생성
'''
def Basic(word_num):
basic_model = tf.keras.Sequential([
tf.keras.layers.Dense(128, input_shape=(word_num,), activation="relu"),
tf.keras.layers.Dense(128, input_shape=(word_num,), activation="relu"),
tf.keras.layers.Dense(1, input_shape=(word_num,), activation="sigmoid")
])
return basic_model
'''
2. 기본 모델에 L1 정규화를 적용
입력층과 히든층에만 적용
'''
def L1(word_num):
l1_model = tf.keras.Sequential([
tf.keras.layers.Dense(128, input_shape=(word_num,), activation="relu",
kernel_regularizer = tf.keras.regularizers.l1(0.001)),
tf.keras.layers.Dense(128, input_shape=(word_num,), activation="relu",
kernel_regularizer = tf.keras.regularizers.l1(0.001)),
tf.keras.layers.Dense(1, input_shape=(word_num,), activation="sigmoid")
])
return l1_model
'''
3. 기본 모델에 L2 정규화를 적용
입력층과 히든층에만 적용
'''
def L2(word_num):
l2_model = tf.keras.Sequential([
tf.keras.layers.Dense(128, input_shape=(word_num,), activation="relu",
kernel_regularizer = tf.keras.regularizers.l2(0.001)),
tf.keras.layers.Dense(128, input_shape=(word_num,), activation="relu",
kernel_regularizer = tf.keras.regularizers.l2(0.001)),
tf.keras.layers.Dense(1, input_shape=(word_num,), activation="sigmoid")
])
return l2_model
'''
4. 세 모델을 불러온 후 학습시키고 테스트 데이터에 대해 평가
'''
def main():
word_num = 100
data_num = 25000
# Keras에 내장되어 있는 imdb 데이터 세트를 불러오고 전처리
(train_data, train_labels), (test_data, test_labels) = tf.keras.datasets.imdb.load_data(num_words = word_num)
train_data = sequences_shaping(train_data, dimension = word_num)
test_data = sequences_shaping(test_data, dimension = word_num)
basic_model = Basic(word_num) # 기본 모델
l1_model = L1(word_num) # L1 정규화를 적용할 모델
l2_model = L2(word_num) # L2 정규화를 적용할 모델
basic_model.compile(loss = "binary_crossentropy", optimizer = "adam", metrics = ["accuracy",
"binary_crossentropy"])
l1_model.compile(loss = "binary_crossentropy", optimizer = "adam", metrics = ["accuracy",
"binary_crossentropy"])
l2_model.compile(loss = "binary_crossentropy", optimizer = "adam", metrics = ["accuracy",
"binary_crossentropy"])
basic_model.summary()
l1_model.summary()
l2_model.summary()
basic_history = basic_model.fit(train_data, train_labels, epochs=20, batch_size= 500, validation_data = (test_data, test_labels), verbose =0)
print('\n')
l1_history = l1_model.fit(train_data, train_labels, epochs=20, batch_size= 500, validation_data = (test_data, test_labels), verbose =0)
print('\n')
l2_history = l2_model.fit(train_data, train_labels, epochs=20, batch_size= 500, validation_data = (test_data, test_labels), verbose =0)
scores_basic = basic_model.evaluate(test_data, test_labels,verbose=0)
scores_l1 = l1_model.evaluate(test_data, test_labels,verbose=0)
scores_l2 = l2_model.evaluate(test_data, test_labels,verbose=0)
print('\nscores_basic: ', scores_basic[-1])
print('scores_l1: ', scores_l1[-1])
print('scores_l2: ', scores_l2[-1])
Visulaize([('Basic', basic_history),('L1 Regularization', l1_history), ('L2 Regularization', l2_history)])
return basic_history, l1_history, l2_history
if __name__ == "__main__":
main()
드롭 아웃(Drop out) 기법
드롭 아웃(Drop Out)은 모델이 과적합되는 것을 막기 위한 가장 보편적인 정규화(Regularization) 기법
데이터를 학습할 때, 일부 퍼셉트론(뉴런)을 랜덤하게 0으로 만들어 모델 내부의 특정 가중치(Weight)에 치중되는 것을 막음 이를 통해 모델이 일부 데이터에 가중되는 것을 막고 일반화된 모델을 만듬 드롭 아웃을 사용하는데 있어 주의할 점은 학습이 끝난 후 테스트 과정에서는 드롭 아웃을 사용하면 안됨
import numpy as np
import tensorflow as tf
from visual import *
import logging, os
logging.disable(logging.WARNING)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
# 데이터를 전처리하는 함수
def sequences_shaping(sequences, dimension):
results = np.zeros((len(sequences), dimension))
for i, word_indices in enumerate(sequences):
results[i, word_indices] = 1.0
return results
'''
1. 드롭 아웃을 적용할 모델과 비교하기 위한
하나의 기본 모델을 자유롭게 생성
'''
def Basic(word_num):
basic_model = tf.keras.Sequential([
tf.keras.layers.Dense(128, input_shape=(word_num,), activation = "relu"),
tf.keras.layers.Dense(128, input_shape=(word_num,), activation = "relu"),
tf.keras.layers.Dense(1, input_shape=(word_num,), activation = "sigmoid")
])
return basic_model
'''
2. 기본 모델에 드롭 아웃 레이어를 추가
일반적으로 마지막 히든층과 출력층 사이에 하나만 추가
드롭 아웃 적용 확률은 자유롭게 설정
'''
def Dropout(word_num):
dropout_model = tf.keras.Sequential([
tf.keras.layers.Dense(128, input_shape=(word_num,), activation = "relu"),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Dense(128, input_shape=(word_num,), activation = "relu"),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Dense(1, input_shape=(word_num,), activation = "sigmoid")
])
return dropout_model
'''
3. 두 모델을 불러온 후 학습시키고 테스트 데이터에 대해 평가
'''
def main():
word_num = 100
data_num = 25000
# Keras에 내장되어 있는 imdb 데이터 세트를 불러오고 전처리
(train_data, train_labels), (test_data, test_labels) = tf.keras.datasets.imdb.load_data(num_words = word_num)
train_data = sequences_shaping(train_data, dimension = word_num)
test_data = sequences_shaping(test_data, dimension = word_num)
basic_model = Basic(word_num) # 기본 모델
dropout_model = Dropout(word_num) # 드롭 아웃을 적용할 모델
basic_model.compile(loss = "binary_crossentropy", optimizer = "adam", metrics = ["accuracy", "binary_crossentropy"])
dropout_model.compile(loss = "binary_crossentropy", optimizer = "adam", metrics = ["accuracy", "binary_crossentropy"])
basic_model.summary()
dropout_model.summary()
basic_history = basic_model.fit(train_data, train_labels, epochs=200, batch_size=500, validation_data=(test_data, test_labels), verbose=0)
print('\n')
dropout_history = dropout_model.fit(train_data, train_labels, epochs=200, batch_size=500, validation_data=(test_data, test_labels), verbose=0)
scores_basic = basic_model.evaluate(test_data, test_labels, verbose=0)
scores_dropout = dropout_model.evaluate(test_data, test_labels, verbose=0)
print('\nscores_basic: ', scores_basic[-1])
print('scores_dropout: ', scores_dropout[-1])
Visulaize([('Basic', basic_history),('Dropout', dropout_history)])
return basic_history, dropout_history
if __name__ == "__main__":
main()
배치 정규화(Batch Normalization)
배치 정규화(Batch Normalization)는 정규화를 모델에 들어가는 입력 데이터뿐만 아니라 모델 내부 히든층의 입력 노드에도 적용 배치 정규화를 적용하면 매 층마다 정규화를 진행하므로 가중치 초기값에 크게 의존하지 않음 즉, 가중치 초기화의 중요도가 감소 또한 과적합을 억제 즉, 즉, 드롭 아웃(Drop out)과 L1, L2 정규화의 필요성이 감소
학습 속도도 빨라짐
import numpy as np
import tensorflow as tf
from visual import *
import logging, os
logging.disable(logging.WARNING)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
np.random.seed(200)
tf.random.set_seed(200)
# 배치 정규화를 적용할 모델과 비교하기 위한 기본 모델
def Basic():
basic_model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(256),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(128),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(512),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(64),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(128),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(256),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
return basic_model
'''
1. 기본 모델에 배치 정규화 레이어를 적용한
모델을 생성합니다. 입력층과 출력층은 그대로 사용
'''
def BN():
bn_model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(256),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(128),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(512),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(64),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(128),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(256),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
return bn_model
'''
2. 두 개의 모델을 불러온 후 학습시키고 테스트 데이터에 대해 평가
'''
def main():
# MNIST 데이터를 불러오고 전처리
mnist = tf.keras.datasets.mnist
(train_data, train_labels), (test_data, test_labels) = mnist.load_data()
train_data, test_data = train_data / 255.0, test_data / 255.0
basic_model = Basic() # 기본 모델
bn_model = BN() # 배치 정규화를 적용할 모델
basic_model.compile(loss ="sparse_categorical_crossentropy",
optimizer = "adam", metrics = ["accuracy"])
bn_model.compile(loss ="sparse_categorical_crossentropy",
optimizer = "adam", metrics = ["accuracy"])
basic_model.summary()
bn_model.summary()
basic_history = basic_model.fit(train_data, train_labels, epochs=20, batch_size= 500, validation_data = (test_data, test_labels), verbose=0)
print('\n')
bn_history = bn_model.fit(train_data, train_labels, epochs=20, batch_size= 500, validation_data = (test_data, test_labels), verbose=0)
scores_basic = basic_model.evaluate(test_data,test_labels)
scores_bn = bn_model.evaluate(test_data,test_labels)
print('\naccuracy_basic: ', scores_basic[-1])
print('accuracy_bn: ', scores_bn[-1])
Visulaize([('Basic', basic_history),('Batch Normalization', bn_history)])
return basic_history, bn_history
if __name__ == "__main__":
main()
'파이썬 이것저것 > 파이썬 딥러닝 관련' 카테고리의 다른 글
| [Python] 딥러닝 자연어 처리를 위한 딥러닝 (0) | 2022.07.15 |
|---|---|
| [Python] 딥러닝 이미지 처리(CNN) (0) | 2022.07.15 |
| [Python] 딥러닝 학습 속도 문제와 최적화 (0) | 2022.07.14 |
| [Python] 딥러닝 텐서플로 모델 구현하기 (0) | 2022.07.14 |
| [Python] 딥러닝 텐서플로(TensorFlow) (0) | 2022.07.14 |