반응형
import tensorflow as tf
# 실행마다 동일한 결과 얻기 위한 랜덤시드 적용
tf.keras.utils.set_random_seed(42)
# 텐서플로 연상을 결정적으로 만든다.
# 시작부분 입력
tf.config.experimental.enable_op_determinism()
손실곡선
In [ ]:
from tensorflow import keras
from sklearn.model_selection import train_test_split
In [ ]:
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
32768/29515 [=================================] - 0s 0us/step
40960/29515 [=========================================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz
26427392/26421880 [==============================] - 0s 0us/step
26435584/26421880 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz
16384/5148 [===============================================================================================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz
4423680/4422102 [==============================] - 0s 0us/step
4431872/4422102 [==============================] - 0s 0us/step
In [ ]:
# 각 픽셀 : 0~ 255 사이의 정수 값을 보유
# -> 255.0 으로 나누어 0~1 사이 값으로 정규화
train_scaled = train_input / 255.0
In [ ]:
# 훈련 데이터셋으로부터 20% 정도의 샘플 데이터를 추출하여 검증 데이터 셋 추출
# -> train_test_split()
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
In [ ]:
# 모델 생성 : 사용자 정의 함수../
def model_fn(a_layer = None):
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation="relu"))
if a_layer:
model.add(a_layer)
model.add(keras.layers.Dense(10, activation="softmax"))
return model
In [ ]:
model = model_fn()
model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_1 (Flatten) (None, 784) 0
dense_2 (Dense) (None, 100) 78500
dense_3 (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________
In [ ]:
model.compile(loss="sparse_categorical_crossentropy", metrics="accuracy")
In [ ]:
history = model.fit(train_scaled, train_target, epochs=5, verbose =0)
In [ ]:
# history : Histroy 객체가 저장
# histroy : 학습 결과 값이 학습 할 때마다 저장
# dict_keys(["loss","accuracy"])
print(history.history.keys())
dict_keys(['loss', 'accuracy'])
In [ ]:
# 손실 : histtory.history["loss"]
import matplotlib.pyplot as plt
plt.plot(history.history["loss"])
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()

In [ ]:
# 정확도 그래프
plt.plot(history.history["accuracy"])
plt.xlabel("epoch")
plt.ylabel("accuracy")
plt.show()

과적합(overfititting) : 훈련, 검증 결과 데이터가 모두 필요
- 학습할 때마다 검증 손실을 계싼하기 위해서 fit에게 검증 데이터를 전달함
- vaildation_data 옵션을 이용하여 전달
- validation_data 에 전달할 경우 검증에 사용할 입력값과 타겟값을 튜플로 전달
In [ ]:
model = model_fn()
model.compile(loss="sparse_categorical_crossentropy", metrics="accuracy")
history = model.fit(train_scaled, train_target, epochs=20, verbose =0,
validation_data = (val_scaled, val_target))
In [ ]:
print(history.history.keys())
# dict_keys(["loss","accuracy","val_loss","val_accuracy"])
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
In [ ]:
# 손실 시각화
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.xlabel("epoch")
plt.ylabel("loss")
plt.legend(["train","val"])
plt.show()

- 과대 적합 : 훈련점수는 좋지만, 테스트 점수가 낮을 경우
- 과소 적합 : 훈련 점수보다, 테스트 점수가 높을 경우, 또는 훈련 점수와 테스트 점수가 모두 현저히 낮을 경우
- 그 외 : 훈련 데이터셋과 테스트 데이터셋이 너무 작을 경우 (즉, 데이터 갯수가 현저히 작을 경우)
- 과대적합의 경우는 검증 손실이 상승하는 시점을 뒤로 늦추는 방법을 통해
- 검증셋에 대한 손실과 정확도를 높일 수 있다.
과대적합 완화
- 옵티마이저 하이퍼 파라미터를 조정
- optimizer = "함수"
- 예) optimizer = "adam" 의 형태
- 이 옵션은 모델 컴파일 시, 미리 설정
- adam 은 적응적 학습율을 적용하기 때문에, 에폭이 진행되면서 학습률 크기를 자동으로 조정해준다.
In [ ]:
model = model_fn()
model.compile(optimizer = "adam",loss="sparse_categorical_crossentropy", metrics="accuracy")
history = model.fit(train_scaled, train_target, epochs=20, verbose =0,
validation_data = (val_scaled, val_target))
In [ ]:
# 완화 되었음
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.xlabel("epoch")
plt.ylabel("loss")
plt.legend(["train","val"])
plt.show()

드롭아웃
- 훈련과정에서 층에 있는 일부 노드(뉴런)을 랜덤하게 꺼내어 과대적합을 막는 개념
- 즉, 노드에 출력값을 0으로 만들어 방지
- Dropout() 레이어를 추가 -> 모델 객체 생성 시
- keras.layers.Dropout()
In [ ]:
model = model_fn(keras.layers.Dropout(0.3)) # 30%
model.summary()
Model: "sequential_7"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_7 (Flatten) (None, 784) 0
dense_14 (Dense) (None, 100) 78500
dropout (Dropout) (None, 100) 0
dense_15 (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________
In [ ]:
model.compile(optimizer = "adam",loss="sparse_categorical_crossentropy", metrics="accuracy")
history = model.fit(train_scaled, train_target, epochs=20, verbose =0,
validation_data = (val_scaled, val_target))
In [ ]:
# 완화 되었음
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.xlabel("epoch")
plt.ylabel("loss")
plt.legend(["train","val"])
plt.show()

모델 저장과 복원
- 모델 저장하기 : 모델 객체의 함수를 이용
- 훈련된 모델의 파라미터만 저장 : save_weights('모델명.h5') <=> load_weights('모델명.h5')
- 훈련된 모델의 구조 및 파라미터까지 저장 : save('모델명.h5') <=> lo
In [ ]:
model = model_fn(keras.layers.Dropout(0.3)) # 30%
model.compile(optimizer = "adam",loss="sparse_categorical_crossentropy", metrics="accuracy")
history = model.fit(train_scaled, train_target, epochs=20, verbose =0,
validation_data = (val_scaled, val_target))
In [ ]:
# 모델의 객체의 save_weights() : 훈련된 모델의 파라미터 저장
model.save_weights("model-weights.h5")
In [ ]:
# 모델 객체의 save() : 훈련된 모델의 구조와 파라미터 저장
model.save("model-while.h5")
In [ ]:
# 코랩에서 두 개 파일 저장 확인
!ls -al *.h5
-rw-r--r-- 1 root root 333448 Jul 14 02:22 model-weights.h5
-rw-r--r-- 1 root root 982664 Jul 14 02:22 model-while.h5
In [ ]:
# 저장될 모델을 이용하여 사용
# 1. 파라미터만 저장한 모델 로드하여 사용 : predict()
# 훈련하지 않은 새로운 모델 생성
model = model_fn(keras.layers.Dropout(0.3))
# 저장된 모델 로드하여 사용
model.load_weights("model-weights.h5")
In [ ]:
import numpy as np
# np.argmax() : predict() 의 결과 값에서 가장 큰 값을 추출하기 위한 함수
# axis 옵션 :
# axis = -1 : 배열의 마지막 차원을 따라 최대값을 추출
# => 검증데이터 셋은 2차원 이기 때문에 마지막 차원은 1
# axis = 0 : 행을 따라 각 열의 최대값의 인덱스
# axis = 1 : 열을 따라 각 행의 최대값의 인덱스
val_labels = np.argmax(model.predict(val_scaled), axis= -1)
# 정확도 : val_labels과 val_target을 비교하여
# 각 위치가 같으면 : 1
# 각 위치가 다르면 : 0
# 따라서 이 결과에 대한 평균이 정확도.....
print(np.mean(val_labels == val_target))
0.887
In [ ]:
# 2. 모델의 구조와 파라미터를 저장한 모델을 사용
model = keras.models.load_model("model-while.h5")
model.evaluate(val_scaled, val_target)
375/375 [==============================] - 2s 3ms/step - loss: 0.3207 - accuracy: 0.8870
Out[ ]:
[0.32070672512054443, 0.8870000243186951]콜백
In [ ]:
# 콜백 : 훈련도중 어떠한 일을 하기 위해 설정
# 예) 가장 낮은 손실이 발생했을 때, 훈련을 멈춘다든지....
# fit() 함수의 callbacks =[체크포인트 객체] 을 이용하여 설정
# 체크포인트 객체 : keras.callbacks.ModelCheckPoint()
# ModelCheckPoint("저장모델명.h5", 체크포인트위치)
# 체크포인트 위치: 만약 훈련결과 점수가 가장 낮은 지점에서 훈련을 멈추고 해당 모델을 저장할 경우,
# save_best_only = True 로 설정
In [ ]:
# 새로운 모델 생성
model = model_fn(keras.layers.Dropout(0.3)) # 30%
model.compile(optimizer = "adam",loss="sparse_categorical_crossentropy", metrics="accuracy")
history = model.fit(train_scaled, train_target, epochs=20, verbose =0,
validation_data = (val_scaled, val_target))
# 체크포인트 객체 생성
checkpoint_cb = keras.callbacks.ModelCheckpoint("best-model.h5", save_best_only=True)
# fit()에 체크포인트 객체 설정
model.fit(train_scaled, train_target, epochs=20, verbose=0,
validation_data = (val_scaled, val_target),
callbacks=[checkpoint_cb])
Out[ ]:
<keras.callbacks.History at 0x7fc3d610cb90>In [ ]:
# 저장된 체크포인트 모델 사용
model = keras.models.load_model("best-model.h5")
model.evaluate(val_scaled, val_target)
375/375 [==============================] - 1s 2ms/step - loss: 0.3143 - accuracy: 0.8898
Out[ ]:
[0.3142765462398529, 0.8897500038146973]In [ ]:
# 설계한 모델의 훈련과정 중, 최상의 시점에서 훈련을 멈추고, 최상의 파라미터를 저장할 경우
# 즉 최고의 훈련 모델을 저장할 경우에는
# ModelCheckPoint 객체와
# EarlyStopping 객체를
# fit() 의 callbacks = []에 [ModelCheckPoint 객체, EarlyStopping 객체] 에 설정
# EarlyStopping 객체 = keras.callbacks.EarlyStopping(patience =?, restore_best_weights= True)
# patience=의 값
# patience=2 설정 했을 경우 : 점수가 두번 이상 향상되지 않으면 훈련 종료
# re
In [ ]:
# 새로운 모델 생성
model = model_fn(keras.layers.Dropout(0.3)) # 30%
model.compile(optimizer = "adam",loss="sparse_categorical_crossentropy", metrics="accuracy")
history = model.fit(train_scaled, train_target, epochs=20, verbose =0,
validation_data = (val_scaled, val_target))
In [ ]:
# 체크포인트 객체 생성
checkpoint_cb = keras.callbacks.ModelCheckpoint("best-model.h5", save_best_only=True)
# 얼리스탑핑 생성
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2,
restore_best_weights=True)
# fit()에 체크포인트 객체 설정
history = model.fit(train_scaled, train_target, epochs=20, verbose=0,
validation_data = (val_scaled, val_target),
callbacks=[checkpoint_cb,early_stopping_cb])
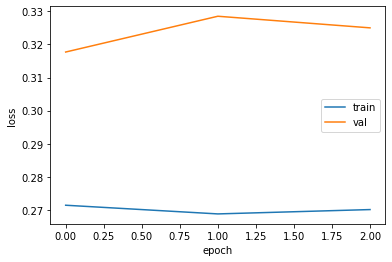
In [ ]:
# 완화 되었음
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.xlabel("epoch")
plt.ylabel("loss")
plt.legend(["train","val"])
plt.show()
'경기도 인공지능 개발 과정 > Python' 카테고리의 다른 글
| [Ptyhon] 딥러닝 활성화 함수, 가중치 정리 (0) | 2022.07.26 |
|---|---|
| [Python] AIFB 강의(가입정보를 활용한 고객 데이터 분석) (0) | 2022.07.18 |
| [Python] 텐서플로_Pooling (0) | 2022.07.13 |
| [Python] 텐서플로_컨볼루전(Conv2D)_실습 (0) | 2022.07.12 |
| [Python] 텐서플로 플래튼 (0) | 2022.07.12 |