0. 개요
가. 패키지 설치 및 라이브러리 호출
import warnings
# 불필요한 경고 출력을 방지합니다.
warnings.filterwarnings('ignore')
import subprocess
import sys
import pandas as pd
import numpy as np
import pickle
import hashlib
def install(package):
subprocess.check_call([sys.executable, "-m", "pip", "install", package])
install("folium")
install("seaborn")
install("xgboost")
나. 강의 목차
1. 데이터 수집
가. 데이터 암호화
#실습 코드 - 파일을 ansan_data 데이터프레임에 로드하세요. 경로명(aidu환경): 'ansan_data.csv'
ansan_data=pd.read_csv("ansan_data.csv")
#head()로 상위 5개의 데이터를 살펴봅니다.
ansan_data.head()
※ 이 데이터는 고객을 식별할 수 없도록 사전에 처리를 거쳤습니다.
hashlib 을 이용한 데이터 암호화
IS, JOIN_SEQ는 암호화가 필요한 항목입니다.
학습데이터는 이미 암호화 되어있으나, 암호화 코드를 실행해보면서 방법을 익힙니다.
#암호화를 위한 함수를 정의합니다.
def encrypt(target):
hashSHA=hashlib.sha256() #SHA256 해시 객체 생성
hashSHA.update(str(target).encode('utf-8')) #해시 값 생성 암호화 대상이 숫자형인 경우에는 문자로 변경해야 한다.
return hashSHA.hexdigest().upper() #해시값 반환
#연습문제 - encrypt 함수를 이용하여 본인 이름을 해쉬값으로 변경하세요
encrypt("성민제")
'537D30E8C014ECB9EDF5BFED130C18A7C7397A359B416ADAEB2F2C58DB3E0EC0'#실습 코드 - 앞서 만든 encrypt 함수를 적용하여 IS컬럼의 값을 암호화 하세요(.apply 함수를 이용하세요)
ansan_data['IS']=ansan_data['IS'].apply(encrypt)
ansan_data.head()
#실습 코드 - 앞서 만든 encrypt 함수를 적용하여 JOIN_SEQ컬럼의 값을 암호화 하세요(.apply 함수를 이용하세요)
ansan_data['JOIN_SEQ']=ansan_data['JOIN_SEQ'].apply(encrypt)
ansan_data['JOIN_SEQ'].head()
0 4ECD4C4BA2746463118E9B3E98C4D60E74D460B38B4BA9...
1 4C59FC639891F337F2C8FCE8F16653732306C672DF87C1...
2 708DB4F33C8CE7A1015FA79CDA42220BF52A14723F3ADE...
3 740E839B30A7BFAF81F10654A28423CDE84F6F0747CA3B...
4 936C726D2B538400D09885A481A886ADF9F0D17BC1B4A2...
Name: JOIN_SEQ, dtype: object값이 암호화 되는 것을 확인할 수 있습니다.
ansan_data.head()
나. 주소에 대한 위경도 좌표 수집
지도시각화를 위해서는 주소에 대한 좌표가 필요합니다.
Aidu 환경에서는 api 호출이 불가능하기 때문에 api호출은 실습하지 않습니다.
api로 수집한 데이터를 간단하게 파싱해보는 것만 실습하겠습니다.
with open('json_data.pickle', 'rb') as f:
json_data = pickle.load(f) # 단 한줄씩 읽어옴
json_data[:10]
[<Response [200]>,
<Response [200]>,
<Response [200]>,
<Response [200]>,
<Response [200]>,
<Response [200]>,
<Response [200]>,
<Response [200]>,
<Response [200]>,
<Response [200]>]<Response [200]> 각각이 json형식을 담고 있습니다.
.json() 함수로 JSON데이터에 접근이 가능합니다.
아래 결과를 보면 [] 리스트와 {} 딕셔너리로 되어있습니다. 즉, index와 key로 접근이 가능합니다.
json_data[0].json()
- 도로명 주소 가져오기
한단계씩 접근해 봅니다.
json_data[0].json()['documents']
json_data[0].json()['documents'][0]
json_data[0].json()['documents'][0]['road_address']['address_name']
- 좌표 가져오기
리스트에서 주소와 경도/위도만 가져와서 데이터프레임으로 만들어 줍니다.
#실습 코드 - json_data의 첫번째 요소에서 좌표를 출력해보세요(x,y)
json_data[0].json()['documents'][0]['road_address']["x"], json_data[0].json()['documents'][0]['road_address']["y"]
address_data=pd.DataFrame([])
#실습 코드 - for문을 활용하여 도로명 주소와 주소에 대한 좌표를 읽어서 address_data에 저장하세요
for i in np.arange(len(json_data)):
address_data=address_data.append([(json_data[i].json()['documents'][0]['road_address']['address_name'],
json_data[i].json()['documents'][0]['road_address']['x'],
json_data[i].json()['documents'][0]['road_address']['y'])],
ignore_index=True)
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-42-3cf2b658be78> in <module>
1 #실습 코드 - for문을 활용하여 도로명 주소와 주소에 대한 좌표를 읽어서 address_data에 저장하세요
2 for i in np.arange(len(json_data)):
----> 3 address_data=address_data.append([(json_data[i].json()['documents'][0]['road_address']['address_name'],
4 json_data[i].json()['documents'][0]['road_address']['x'],
5 json_data[i].json()['documents'][0]['road_address']['y'])],
IndexError: list index out of range에러가 발생합니다. (주소에 대한 위/경도값을 api에서 가져오지 못한 경우)
json_data[18].json()
{'documents': [],
'meta': {'is_end': True, 'pageable_count': 0, 'total_count': 0}}#실습 코드 - for문과 if문을 활용하여 도로명 주소와 주소에 대한 좌표를 읽어서 address_data에 저장하세요
for i in np.arange(len(json_data)):
if json_data[i].json()['documents']!=[]: #주소가 조회되지 않은 경우가 존재하므로 제외함
address_data = address_data.append([(json_data[i].json()["documents"][0]["road_address"]["address_name"],
json_data[i].json()["documents"][0]["road_address"]["x"],
json_data[i].json()["documents"][0]["road_address"]["y"])],
ignore_index=True)
# 코드를 완성하세요.
address_data
| 경기 안산시 단원구 꽃우물길 27 | 126.821475069242 | 37.353274333416 |
| 경기 안산시 단원구 마조금길 36-11 | 126.582792941775 | 37.2236009338678 |
| 경기 안산시 단원구 선삼로5길 24 | 126.81262087183 | 37.3462208193513 |
| 경기 안산시 단원구 원당길 4-12 | 126.81426060651 | 37.3136263617497 |
253 rows × 3 columns
위와 같이 주소에 대한 좌표를 얻어서 저장할 수 있습니다.
ansan_data의 위경도 좌표는 이렇게 만들어졌습니다.
ansan_data.iloc[:,-3:]
| 경기도 안산시 도로_300 41 | 126.812665 | 37.306694 |
| 경기도 안산시 도로_135 215 | 126.834569 | 37.311247 |
| 경기도 안산시 도로_124 80 | 126.818370 | 37.305672 |
| 경기도 안산시 도로_139 157 | 126.836629 | 37.305891 |
| 경기도 안산시 도로_364 29 | 126.838281 | 37.326341 |
| ... | ... | ... |
| 경기도 안산시 도로_380 47 | 126.801111 | 37.316470 |
| 경기도 안산시 도로_39 326 | 126.786731 | 37.323545 |
| 경기도 안산시 도로_39 326 | 126.786664 | 37.323128 |
| 경기도 안산시 도로_39 326 | 126.787017 | 37.323861 |
| 경기도 안산시 도로_13 69 | 126.841267 | 37.317351 |
177287 rows × 3 columns
위와 같이 좌표를 얻어서 BIDW데이터에 붙여주었습니다.
아래가 최종 수집된 데이터입니다.
ansan_data.head(3)
| 2020-05-11 | 187E67F5E3D6893386AF54D8880752539691211BD52A08... | 개인 | _ | ㆍ값없음 | 4ECD4C4BA2746463118E9B3E98C4D60E74D460B38B4BA9... | 059Z | 내선전화 | 2003-07-19 | ㆍ값없음 | ... | R00050282 | 도로_300 | 아파트1067 | 41 | 0 | |||||
3 rows × 22 columns
※ 컬럼 설명
- DATE : 데이터 생성일자
- IS : 식별번호
- TYPE : 고객 유형
- TYPE_DTL : 상세 분류 코드
- 상세분류2 : 상세 분류 코드 한글명
- JOIN_SEQ: 가입일련번호
- PRODUCT : 상품코드
- PRODUCT_NM : 상품코드 한글명
- JOIN_DATE : 가입일자
- C_PERIOD_DATE : 약정기간
- B_DONG : 법정동
- B_DONG_ADD : 행정구역+법정동
- ROAD_NO : 도로명번호
- ROAD_NM : 도로명
- BUILDING_NM : 건물명
- BUILDING_NO1 : 건물 본번
- BUILDING_NO2 : 건물 부번
- ROAD_NM_ADD : 행정구역+도로명
- CNT : 지표
- F_ADDR : 도로명주소전체
- lon: 경도
- lat: 위도
2. 데이터 전처리
어떤 데이터인지 한번 살펴봅니다.
ansan_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 177287 entries, 0 to 177286
Data columns (total 22 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 DATE 177287 non-null object
1 IS 177287 non-null object
2 TYPE 177287 non-null object
3 TYPE_DTL 177287 non-null object
4 상세분류2 177287 non-null object
5 JOIN_SEQ 177287 non-null object
6 PRODUCT 177287 non-null object
7 PRODUCT_NM 177287 non-null object
8 JOIN_DATE 177228 non-null object
9 C_PERIOD 177287 non-null object
10 B_DONG 177287 non-null object
11 B_DONG_ADD 177287 non-null object
12 ROAD_NO 177287 non-null object
13 ROAD_NM 177287 non-null object
14 BUILDING_NM 144578 non-null object
15 BUILDING_NO1 177287 non-null int64
16 BUILDING_NO2 177287 non-null int64
17 ROAD_NM_ADD 177287 non-null object
18 CNT 177287 non-null int64
19 F_ADDR 177287 non-null object
20 lon 177279 non-null float64
21 lat 177279 non-null float64
dtypes: float64(2), int64(3), object(17)
memory usage: 29.8+ MB
가.결측값 제거
JOIN_DATE, lon, lat에 결측치가 존재함을 알수 있습니다. 컬럼별로 아래와 같이 결측치를 처리합니다.
- JOIN_DATE: 사용하지 않을 데이터이므로 열을 지우겠습니다.
- BUILDING_NM : 건물명은 실제로 값이 존재하지 않을 수 있으므로 공란으로 두겠습니다.
- lon, lat : 주소에 좌표가 없는 것은 있을 수 없으므로 해당 행을 삭제하겠습니다.
ansan_data.head()
| 2020-05-11 | 187E67F5E3D6893386AF54D8880752539691211BD52A08... | 개인 | _ | ㆍ값없음 | 4ECD4C4BA2746463118E9B3E98C4D60E74D460B38B4BA9... | 059Z | 내선전화 | 2003-07-19 | ㆍ값없음 | ... | R00050282 | 도로_300 | 아파트1067 | 41 | 0 | 1 | 126.812665 | 37.306694 | ||
| 2020-05-11 | 1BF44EBE97B481D28E3B774E778E0E6406116EFDEC29D3... | 개인 | _ | ㆍ값없음 | 4C59FC639891F337F2C8FCE8F16653732306C672DF87C1... | 059Z | 내선전화 | 2003-07-25 | ㆍ값없음 | ... | R00050210 | 도로_135 | 상가979 | 215 | 0 | 1 | 126.834569 | 37.311247 | ||
| 2020-05-11 | F2AFF7038C1740FD05445CB2E37DB5E116A459DD10BFCF... | 개인 | _ | ㆍ값없음 | 708DB4F33C8CE7A1015FA79CDA42220BF52A14723F3ADE... | 059Z | 내선전화 | 2003-07-28 | ㆍ값없음 | ... | R00050201 | 도로_124 | 아파트1046 | 80 | 0 | 1 | 126.818370 | 37.305672 | ||
| 2020-05-11 | CBECCD2E091BDA7AB2395D8146F3B608FD72B6AEC54319... | 개인 | _ | ㆍ값없음 | 740E839B30A7BFAF81F10654A28423CDE84F6F0747CA3B... | 059Z | 내선전화 | 2003-07-30 | ㆍ값없음 | ... | R00050252 | 도로_139 | 상가984 | 157 | 0 | 1 | 126.836629 | 37.305891 | ||
| 2020-05-11 | D6E56F9244AA80E03C48DD42AC0CE106CB353CFEC5CBFA... | 개인 | _ | ㆍ값없음 | 936C726D2B538400D09885A481A886ADF9F0D17BC1B4A2... | 059Z | 내선전화 | 2003-08-04 | ㆍ값없음 | ... | R00050219 | 도로_364 | 아파트1055 | 29 | 0 | 1 | 126.838281 | 37.326341 |
5 rows × 22 columns
i) JOIN_DATE 열을 삭제합니다.
결측치 제거하는 김에 불필요한 컬럼도 함께 삭제하겠습니다.('JOIN_DATE','DATE','C_PERIOD','B_DONG','B_DONG_ADD','ROAD_NM_ADD','CNT')
#실습 코드 - 'JOIN_DATE','DATE','C_PERIOD','B_DONG','B_DONG_ADD','ROAD_NM_ADD','CNT' 열을 삭제하세요 (.drop()을 사용하세요.)
ansan_data.drop(['JOIN_DATE','DATE','C_PERIOD','B_DONG','B_DONG_ADD','ROAD_NM_ADD','CNT'] ,axis=1,inplace=True)
ii) BUILDING_NM 열은 공란으로 둡니다.
#실습 코드 - BUILDING_NM 열의 NaN값을 확인합니다. (.isna()를 사용하세요.)
ansan_data["BUILDING_NM"].isna().sum()
#코드를 완성하세요.
32709BUILDING_NM에 NaN이 들어가 있는 것이 보입니다. ""로 값을 변경합니다.
#실습 코드 - NaN을 공란으로 바꿔줍니다. (.fillna()를 사용하세요)
ansan_data['BUILDING_NM'].fillna("",inplace=True )
ansan_data[ansan_data['BUILDING_NM'].isna()]
결측값이 사라졌습니다.
iii) lon, lat은 결측값이 있는 행을 삭제합니다.
#실습 코드 - 결측값이 있는 행을 삭제합니다.(.dropna() 를 사용하세요)
ansan_data.dropna(axis=0,inplace=True)
ansan_data.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 177279 entries, 0 to 177286
Data columns (total 15 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 IS 177279 non-null object
1 TYPE 177279 non-null object
2 TYPE_DTL 177279 non-null object
3 상세분류2 177279 non-null object
4 JOIN_SEQ 177279 non-null object
5 PRODUCT 177279 non-null object
6 PRODUCT_NM 177279 non-null object
7 ROAD_NO 177279 non-null object
8 ROAD_NM 177279 non-null object
9 BUILDING_NM 177279 non-null object
10 BUILDING_NO1 177279 non-null int64
11 BUILDING_NO2 177279 non-null int64
12 F_ADDR 177279 non-null object
13 lon 177279 non-null float64
14 lat 177279 non-null float64
dtypes: float64(2), int64(2), object(11)
memory usage: 21.6+ MB
이제 모든 결측치가 모두 사라졌습니다.
나. 중복 제거
데이터를 삭제한 경우 중복이 발생할 수 있습니다.
#실습 코드 - 데이터프레임의 중복을 제거합니다.(drop_duplicates()를 사용하세요)
ansan_data.drop_duplicates(inplace=True)
ansan_data.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 177279 entries, 0 to 177286
Data columns (total 15 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 IS 177279 non-null object
1 TYPE 177279 non-null object
2 TYPE_DTL 177279 non-null object
3 상세분류2 177279 non-null object
4 JOIN_SEQ 177279 non-null object
5 PRODUCT 177279 non-null object
6 PRODUCT_NM 177279 non-null object
7 ROAD_NO 177279 non-null object
8 ROAD_NM 177279 non-null object
9 BUILDING_NM 177279 non-null object
10 BUILDING_NO1 177279 non-null int64
11 BUILDING_NO2 177279 non-null int64
12 F_ADDR 177279 non-null object
13 lon 177279 non-null float64
14 lat 177279 non-null float64
dtypes: float64(2), int64(2), object(11)
memory usage: 21.6+ MB
중복이 존재하지 않습니다.
다. 컬럼명 변경.
한글로된 컬럼명을 영어로 변경합니다.
#실습 코드 - 상세분류2 --> TYPE_DTL_NM로 컬럼명을 변경합니다.rename 함수를 이용하세요. 입력값은 {변경전컬럼명,변경후컬럼명} 이며, axis=1 옵션을 주어야 합니다.
ansan_data=ansan_data.rename(columns = {"상세분류2":"TYPE_DTL_NM"})
ansan_data
| 187E67F5E3D6893386AF54D8880752539691211BD52A08... | 개인 | _ | ㆍ값없음 | 4ECD4C4BA2746463118E9B3E98C4D60E74D460B38B4BA9... | 059Z | 내선전화 | R00050282 | 41 | 0 | 126.812665 | 37.306694 | |||
| 1BF44EBE97B481D28E3B774E778E0E6406116EFDEC29D3... | 개인 | _ | ㆍ값없음 | 4C59FC639891F337F2C8FCE8F16653732306C672DF87C1... | 059Z | 내선전화 | R00050210 | 215 | 0 | 126.834569 | 37.311247 | |||
| F2AFF7038C1740FD05445CB2E37DB5E116A459DD10BFCF... | 개인 | _ | ㆍ값없음 | 708DB4F33C8CE7A1015FA79CDA42220BF52A14723F3ADE... | 059Z | 내선전화 | R00050201 | 80 | 0 | 126.818370 | 37.305672 | |||
| CBECCD2E091BDA7AB2395D8146F3B608FD72B6AEC54319... | 개인 | _ | ㆍ값없음 | 740E839B30A7BFAF81F10654A28423CDE84F6F0747CA3B... | 059Z | 내선전화 | R00050252 | 157 | 0 | 126.836629 | 37.305891 | |||
| D6E56F9244AA80E03C48DD42AC0CE106CB353CFEC5CBFA... | 개인 | _ | ㆍ값없음 | 936C726D2B538400D09885A481A886ADF9F0D17BC1B4A2... | 059Z | 내선전화 | R00050219 | 29 | 0 | 126.838281 | 37.326341 | |||
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | |||
| D57D266B1D0A4A5C94CCCC46B37AFB6ABD92CF614E0F41... | 개인사업자 | 90029 | 가치 | CC9A47350AD7B49AEA972F5FACAD1409A24412CC8D91D3... | 0V2101 | biz_인터넷전화_A | R00050226 | 47 | 0 | 126.801111 | 37.316470 | |||
| 11089D77B49DFE8070D277046F9E85F89169598C99A8F6... | 개인 | 10003 | MASS | 8C6CC1EB8DAE63629739503738A7C66B1E07A5F6520CCD... | 0501 | 일반전화 | R00050199 | 326 | 0 | 126.786731 | 37.323545 | |||
| 9B3AA16230A5AFC064816A7849993340B1FA61D5ABB479... | 개인 | 10003 | MASS | F267C5BD0AB55EA7D25A9EC2D47FBEB14CFC7F39ED27FD... | 088M01 | 인터넷_A | R00050199 | 326 | 0 | 126.786664 | 37.323128 | |||
| 1AB4BD42ED3CE52CE539BBA55C2F06E2F25AF0222BA5F8... | 개인 | 10003 | MASS | D3D10D98C705895D3C54483265CB0D8B8ED7B87BE2866F... | 2PH601 | IPTV_A | R00050199 | 326 | 0 | 126.787017 | 37.323861 | |||
| 272CF87992C562F626E0DCF2EEA15B2EE3404BFED94079... | 개인 | 10003 | MASS | 8393029F081E3E42261F2ED82EA8FA1745EA94960F4E3F... | 088L01 | 인터넷_E | R00050331 | 69 | 0 | 126.841267 | 37.317351 |
177279 rows × 15 columns
라.Feature Engineering
i) Domain지식 - 데이터 삭제
- 059Z-내선전화는 요금을 납부하지 않으며, 모회선에 종속되어 세금계산서 발급 대상이 아니므로 제외합니다.
#실습 코드 PRODUCT가 '059Z'인 데이터를 삭제합니다. ('059Z'가 아닌 데이터만 가져옵니다)
ansan_data=ansan_data.loc[(ansan_data['PRODUCT']!='059Z')]
ansan_data.head(3)
| 2403D35D92928C792A2BE8391283EF704E9E7652F7D23A... | 개인사업자 | 10019 | 가치 | 8BBB8E2A3A4BAAFA74413364738AF067A00B2EFC4BF9A4... | 088M01 | 인터넷_A | R00050230 | 도로_395 | 65 | 0 | 126.738316 | 37.319408 | ||
| 3A985D28A2D0655B534E6C479D076BA860CC1E0A6AA858... | 개인사업자 | 10019 | 가치 | 5956A41EAD4F67FC5BA589790334CEE2207CF5FAAEAEF9... | 0V0201 | 인터넷전화_A | R00050230 | 도로_395 | 65 | 0 | 126.739371 | 37.318065 | ||
| 29A2442FCF593EA28A6A0BCD2B6B13A938180232B8B337... | 개인사업자 | 10019 | 가치 | B96DDD5726D3DBFFFD50CA743C2B9147AC56B15038ECB3... | 0501 | 일반전화 | R00050230 | 도로_395 | 65 | 0 | 126.738734 | 37.318752 |
ii) Domain지식 - 데이터 수정
- 유형별 데이터를 살펴봅니다.
#실습 코드 - TYPE과 TYPE_DTL_NM을 .groupby() 함수를 이용해서 살펴봅니다. > count() 사용
pd.DataFrame(ansan_data.groupby(["TYPE","TYPE_DTL_NM"])['IS'].count())
| 826 |
| 42223 |
| 1088 |
| 18081 |
| 19169 |
| 20571 |
| 98 |
| 5 |
| 10 |
| 554 |
| 112 |
| 15993 |
| 306 |
| 56 |
| 6536 |
| 1 |
| 12 |
| 95 |
| 1 |
| 9704 |
| 9 |
| 16349 |
| 14 |
| 8748 |
| 14779 |
| 5 |
| 640 |
| 38 |
| 1256 |
- TYPE은 개인/개인사업자/공공기관/기타/법인사업자/정식단체로 분류되는데, 공공기관/기타/법인사업자/정식단체는 구분하는 것이 의미가 없으므로 "법인"으로 통합합니다.
ansan_data.loc[(ansan_data['TYPE']=='공공기관')|
(ansan_data['TYPE']=='기타') |
(ansan_data['TYPE']=='법인사업자')|
(ansan_data['TYPE']=='정식단체'),'TYPE']
21014 법인사업자
21027 법인사업자
21028 법인사업자
21029 법인사업자
21030 법인사업자
...
177272 법인사업자
177273 법인사업자
177277 법인사업자
177278 법인사업자
177279 법인사업자
Name: TYPE, Length: 58243, dtype: objectansan_data.loc[(ansan_data['TYPE']=='공공기관')|
(ansan_data['TYPE']=='기타') |
(ansan_data['TYPE']=='법인사업자')|
(ansan_data['TYPE']=='정식단체'),'TYPE'] = '법인'
- 명의자(TYPE)는 개인이지만, 실제로는 사업자가 연결되어있을 수 있습니다. 고객세부유형을 보면, 가치/AM/CORE/법인은 실제로는 사업자일 것입니다. 실제 데이터를 살펴보면, "가치"는 개인사업자이고, AM/CORE도 기업의 입점업체이거나, 지점으로 개인사업자일 것으로 보이므로, 해당 건들을 전부 개인사업자로 변경하겠습니다.
※고객 세부유형의 의미: MASS(일반개인고객)/ 가치(소상공인) / AM(대기업) /CORE(중견기업) / 법인(미분류 법인)
#실습 코드 - 앞의 코드를 사용하여 TYPE이 '개인'이면서 TYPE_DTL_NM이 'AM','CORE','가치','법인'인 경우 '개인사업자'로 변경해줍니다.
ansan_data.loc[(ansan_data["TYPE"] == "개인")
& ((ansan_data['TYPE_DTL_NM']=='AM')
|(ansan_data['TYPE_DTL_NM']=='CORE')
|(ansan_data['TYPE_DTL_NM']=='가치')
|(ansan_data['TYPE_DTL_NM']=='법인')),'TYPE'] = '개인사업자'
- TYPE_DTL_NM 이 ㆍ값없음 인 경우도 살펴보겠습니다.
BUILDING_NM을 보니 개인사업자입니다. 개인사업자로 변경하겠습니다.
ansan_data.loc[ansan_data['TYPE_DTL_NM']=='ㆍ값없음']
| 187E67F5E3D6893386AF54D8880752539691211BD52A08... | 개인 | _ | ㆍ값없음 | 4ECD4C4BA2746463118E9B3E98C4D60E74D460B38B4BA9... | 059Z | 내선전화 | R00050282 | 41 | 0 | 126.812665 | 37.306694 | |||
| 1BF44EBE97B481D28E3B774E778E0E6406116EFDEC29D3... | 개인 | _ | ㆍ값없음 | 4C59FC639891F337F2C8FCE8F16653732306C672DF87C1... | 059Z | 내선전화 | R00050210 | 215 | 0 | 126.834569 | 37.311247 | |||
| F2AFF7038C1740FD05445CB2E37DB5E116A459DD10BFCF... | 개인 | _ | ㆍ값없음 | 708DB4F33C8CE7A1015FA79CDA42220BF52A14723F3ADE... | 059Z | 내선전화 | R00050201 | 80 | 0 | 126.818370 | 37.305672 | |||
| CBECCD2E091BDA7AB2395D8146F3B608FD72B6AEC54319... | 개인 | _ | ㆍ값없음 | 740E839B30A7BFAF81F10654A28423CDE84F6F0747CA3B... | 059Z | 내선전화 | R00050252 | 157 | 0 | 126.836629 | 37.305891 | |||
| D6E56F9244AA80E03C48DD42AC0CE106CB353CFEC5CBFA... | 개인 | _ | ㆍ값없음 | 936C726D2B538400D09885A481A886ADF9F0D17BC1B4A2... | 059Z | 내선전화 | R00050219 | 29 | 0 | 126.838281 | 37.326341 | |||
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | |||
| 970FE6C3311886B570B67ABBED6FF32B6025A1594B920B... | 개인 | _ | ㆍ값없음 | 516D03DF33AF3E723D2288FDAAC53EEE30C8DA18E532FF... | 059Z | 내선전화 | R00050268 | 49 | 0 | 126.811308 | 37.303106 | |||
| A49DCE9AC6AB3E3013F7C2CC9B2A1D9F07A1A793C43EF4... | 개인 | _ | ㆍ값없음 | F50CF2DEF9D1449EC91BFB6D4E0D86CFBA6B4E13003CBB... | 059Z | 내선전화 | R00050210 | 245 | 0 | 126.837719 | 37.311212 | |||
| C5048D7B1F232A7FF919D0893746DFBC9DC48F55F95D09... | 개인 | _ | ㆍ값없음 | 5E6A68690AB43507B80C89C22F5D4F088CA87F7EE66171... | 059Z | 내선전화 | R00050212 | 45 | 0 | 126.825612 | 37.309489 | |||
| B359AA8A0C05054D60A12D15B8DAB421731B8442658270... | 개인 | _ | ㆍ값없음 | D20A733ACE41147B1B4D0764E94C0E05353C321435C67E... | 088M01 | 인터넷_A | R00050332 | 38 | 0 | 126.834456 | 37.316762 | |||
| 7D9DF6E18137AD4927E9DABC461F5BAF039CA7E99C71C5... | 개인 | _ | ㆍ값없음 | 06FAF031F8C8C5A1555CE0E656D701F60829A37DCA295A... | 2PHA01 | IPTV_B | R00050332 | 38 | 0 | 126.835585 | 37.317674 |
19169 rows × 15 columns
#실습 코드 - TYPE이 '개인'이면서(&) TYPE_DTL_NM이 '값없음'인 경우 개인사업자로 변경합니다.
ansan_data.loc[(ansan_data["TYPE"] == "개인") & (ansan_data["TYPE_DTL_NM"]=='ㆍ값없음'),'TYPE']='개인사업자'
ansan_data.loc[ansan_data['TYPE_DTL_NM']=='ㆍ값없음']
| 187E67F5E3D6893386AF54D8880752539691211BD52A08... | 개인사업자 | _ | ㆍ값없음 | 4ECD4C4BA2746463118E9B3E98C4D60E74D460B38B4BA9... | 059Z | 내선전화 | R00050282 | 41 | 0 | 126.812665 | 37.306694 | |||
| 1BF44EBE97B481D28E3B774E778E0E6406116EFDEC29D3... | 개인사업자 | _ | ㆍ값없음 | 4C59FC639891F337F2C8FCE8F16653732306C672DF87C1... | 059Z | 내선전화 | R00050210 | 215 | 0 | 126.834569 | 37.311247 | |||
| F2AFF7038C1740FD05445CB2E37DB5E116A459DD10BFCF... | 개인사업자 | _ | ㆍ값없음 | 708DB4F33C8CE7A1015FA79CDA42220BF52A14723F3ADE... | 059Z | 내선전화 | R00050201 | 80 | 0 | 126.818370 | 37.305672 | |||
| CBECCD2E091BDA7AB2395D8146F3B608FD72B6AEC54319... | 개인사업자 | _ | ㆍ값없음 | 740E839B30A7BFAF81F10654A28423CDE84F6F0747CA3B... | 059Z | 내선전화 | R00050252 | 157 | 0 | 126.836629 | 37.305891 | |||
| D6E56F9244AA80E03C48DD42AC0CE106CB353CFEC5CBFA... | 개인사업자 | _ | ㆍ값없음 | 936C726D2B538400D09885A481A886ADF9F0D17BC1B4A2... | 059Z | 내선전화 | R00050219 | 29 | 0 | 126.838281 | 37.326341 | |||
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | |||
| 970FE6C3311886B570B67ABBED6FF32B6025A1594B920B... | 개인사업자 | _ | ㆍ값없음 | 516D03DF33AF3E723D2288FDAAC53EEE30C8DA18E532FF... | 059Z | 내선전화 | R00050268 | 49 | 0 | 126.811308 | 37.303106 | |||
| A49DCE9AC6AB3E3013F7C2CC9B2A1D9F07A1A793C43EF4... | 개인사업자 | _ | ㆍ값없음 | F50CF2DEF9D1449EC91BFB6D4E0D86CFBA6B4E13003CBB... | 059Z | 내선전화 | R00050210 | 245 | 0 | 126.837719 | 37.311212 | |||
| C5048D7B1F232A7FF919D0893746DFBC9DC48F55F95D09... | 개인사업자 | _ | ㆍ값없음 | 5E6A68690AB43507B80C89C22F5D4F088CA87F7EE66171... | 059Z | 내선전화 | R00050212 | 45 | 0 | 126.825612 | 37.309489 | |||
| B359AA8A0C05054D60A12D15B8DAB421731B8442658270... | 개인사업자 | _ | ㆍ값없음 | D20A733ACE41147B1B4D0764E94C0E05353C321435C67E... | 088M01 | 인터넷_A | R00050332 | 38 | 0 | 126.834456 | 37.316762 | |||
| 7D9DF6E18137AD4927E9DABC461F5BAF039CA7E99C71C5... | 개인사업자 | _ | ㆍ값없음 | 06FAF031F8C8C5A1555CE0E656D701F60829A37DCA295A... | 2PHA01 | IPTV_B | R00050332 | 38 | 0 | 126.835585 | 37.317674 |
19169 rows × 15 columns
- 삭제된 데이터가 있으니 index를 리셋합니다.
#실습 코드 - index를 리셋하세요
ansan_data.reset_index(drop=True,inplace=True)
- 전처리가 완료되었습니다.
ansan_data.groupby('TYPE')['IS'].count()
TYPE
개인 60304
개인사업자 58732
법인 58243
Name: IS, dtype: int64마.데이터 저장
#실습 코드 - to_csv 함수를 이용하여 ansan_data 를 CSV파일로 저장합니다. 경로명: 'ansan_data_pre.csv'
ansan_data.to_csv('ansan_data_pre.csv')3. 데이터 시각화
가. Seaborn Barplot을 통한 탐색
- seaborn으로 barplot을 그려서 상품의 분포를 탐색해보겠습니다.
i) 한글 폰트 설정
from matplotlib import pyplot as plt
import seaborn as sns
import matplotlib.font_manager as fm
어떤 폰트가 설치되어있는지 확인합니다.
fm.get_fontconfig_fonts()
['/usr/share/fonts/truetype/dejavu/DejaVuSans-Bold.ttf',
'/usr/share/fonts/truetype/nanum/NanumGothicCoding-Bold.ttf',
'/usr/share/fonts/truetype/dejavu/DejaVuSans.ttf',
'/usr/share/fonts/truetype/dejavu/DejaVuSansMono-Bold.ttf',
'/usr/share/fonts/truetype/dejavu/DejaVuSerif-Bold.ttf',
'/usr/share/fonts/truetype/nanum/NanumGothicCoding.ttf',
'/usr/share/fonts/truetype/dejavu/DejaVuSerif.ttf',
'/usr/share/fonts/truetype/dejavu/DejaVuSansMono.ttf']NanumGothicCoding이라는 폰트를 쓰겠습니다.
plt.rc('font',family = 'NanumGothicCoding')
캔버스 사이즈도 키워줍니다.
plt.rcParams["figure.figsize"]=(12,9)
ii) barplot
- 고객유형과 상품별로 groupby를 해봅니다.
pd.DataFrame(ansan_data.groupby(['TYPE','PRODUCT_NM'])['PRODUCT'].count()).sort_values(by=['TYPE','PRODUCT'],
ascending=False)
| 18810 |
| 8716 |
| 4848 |
| 3994 |
| 3706 |
| ... |
| 1 |
| 1 |
| 1 |
| 1 |
| 1 |
414 rows × 1 columns
#실습 코드 - TYPE과 PRODUCT_NM기준으로 groupby 하고, type과 product 값 기준으로 내림차순 정렬(sort_values), index는 리셋 하세요(reset_index)
prod_stat=pd.DataFrame(ansan_data.groupby(["TYPE","PRODUCT_NM"])['PRODUCT'].count()).sort_values(by=["TYPE","PRODUCT"],
ascending=False).reset_index()
prod_stat
| 법인 | biz_일반전화_A | 18810 |
| 법인 | 일반전화 | 8716 |
| 법인 | 전용회선_A | 4848 |
| 법인 | biz_인터넷전화_B | 3994 |
| 법인 | biz_일반전화_B | 3706 |
| ... | ... | ... |
| 개인 | 상품_38 | 1 |
| 개인 | 상품_40 | 1 |
| 개인 | 상품_45 | 1 |
| 개인 | 상품_49 | 1 |
| 개인 | 상품_81 | 1 |
414 rows × 3 columns
- 고객/상품별 건수가 컬럼명이 PRODUCT이니 혼동이 옵니다. 컬럼명을 변경해주겠습니다.
prod_stat = prod_stat.rename(columns={'PRODUCT':'CNT'})
prod_stat
| 법인 | biz_일반전화_A | 18810 |
| 법인 | 일반전화 | 8716 |
| 법인 | 전용회선_A | 4848 |
| 법인 | biz_인터넷전화_B | 3994 |
| 법인 | biz_일반전화_B | 3706 |
| ... | ... | ... |
| 개인 | 상품_38 | 1 |
| 개인 | 상품_40 | 1 |
| 개인 | 상품_45 | 1 |
| 개인 | 상품_49 | 1 |
| 개인 | 상품_81 | 1 |
414 rows × 3 columns
- seaborn.barplot Parameters
x, y: x축, y축이 되는 feature를 넣어줍니다.
data : 그래프를 그릴 데이터
- subplot(m,n,p): m행 n열로 그래프를 배치합니다. p는 mxn 그리드 중 현재 그리는 그래프의 위치를 의미합니다.
#실습 코드 - x축은 PRODUCT_NM, y축은 CNT가 되도록 개인, 개인사업자, 법인에 대하여 barplot 그래프를 그리세요.
i=1
for c_type in ['개인','개인사업자','법인']:
plt.subplot(3,1,i)
graph_data=prod_stat[prod_stat['TYPE']==c_type]
#barplot을 그리세요.#
sns.barplot(x="PRODUCT_NM" ,y="CNT", data=graph_data)
i=i+1
plt.show()

상품이 매우 많다는 것만 알겠습니다. 조금씩 고쳐보겠습니다.
iii) 상품 통합
상품이 너무 많으니, 비중이 작은 상품을 하나로 묶어서 "기타 상품"으로 처리하겠습니다.
상품명을 기타함수로 변경하는 함수를 정의합니다.
#대상이 되는 Dataframe과 기타상품을 구분하는 임계값을 입력으로 받습니다.
def etctoetc(df,threshold):
total_cnt = df['CNT'].sum()
cnt=0
for n in df.index:
cnt=cnt+df.loc[n,'CNT'] #루프를 돌때마다 cnt의 값을 PRODUCT만큼 증가시킴
if(cnt > total_cnt*threshold): #cnt의 값이 total_cnt*threshold보다 크면
df.loc[n:,'PRODUCT_NM'] = '기타상품' #n번 인덱스 이후의 PRODUCT_NM을 '기타상품'으로 상품명을 변경
break
#기타상품으로 변경된 상품을 하나로 합쳐줌
df = pd.DataFrame(df.groupby(['TYPE','PRODUCT_NM'])['CNT'].sum()).reset_index()
#데이터를 정렬할 때 기타상품이 가장 뒤에 오도록 수정
df2 = df.loc[df['PRODUCT_NM']=='기타상품',:]
df3 = df.loc[df['PRODUCT_NM']!='기타상품',:].sort_values(by=['CNT'], ascending=False)
df4= pd.concat([df3,df2],sort=False).reset_index(drop=True)
return df4
위 함수를 적용해서 다시 그려보겠습니다.
#실습 코드 - x축은 PRODUCT_NM, y축은 CNT가 되도록 개인, 개인사업자, 법인에 대하여 barplot 그래프를 그리세요.
i=1
for c_type in ['개인','개인사업자','법인']:
plt.subplot(3,1,i)
graph_data=etctoetc(prod_stat[prod_stat['TYPE']==c_type],0.9)
sns.barplot(x="PRODUCT_NM" ,y="CNT", data=graph_data)
i=i+1
plt.show()

iv) 그래프 수정
- 상품명이 겹쳐보입니다. 이럴 때는 가로 그래프로 그리면 됩니다.
- 간격이 좁습니다. 조금 그래프를 키우겠습니다.
- title 추가합니다.
#실습 코드 - y축은 PRODUCT_NM, x축은 CNT가 되도록 개인, 개인사업자, 법인에 대하여 barplot 그래프를 그리세요.
plt.rcParams["figure.figsize"]=(12,15)
i=1
for c_type in ['개인','개인사업자','법인']:
plt.subplot(3,1,i)
plt.title(c_type+' 주요 사용 상품')
graph_data=etctoetc(prod_stat[prod_stat['TYPE']==c_type],0.9)
#barplot을 그리세요.#
sns.barplot(x="PRODUCT_NM" ,y="CNT", data=graph_data)
i=i+1
plt.show()

개인은 Mass상품, 개인사업자는 Biz 상품과 Mass상품 혼용, 법인은 Biz 상품 위주로 사용하여
고객유형 별로 사용하는 상품에 차이가 있음을 확인할 수 있습니다.
나. Folium을 이용한 지도시각화
이제 우리가 가진 데이터를 지도위에 올려보겠습니다.
i) Folium 기초
일단 지도를 불러와야 합니다.
지도는 folium 패키지를 사용하여 불러오겠습니다. (google/kakao/naver/공공 API에서 지도를 불러올 수도 있겠지만, Aidu에서 외부연동이 불가능합니다.)
import folium
지도의 중심점을 위경도 좌표로 지정하고, 지도의 배율을 지정하겠습니다. (작을 수록 저배율) 우리가 가진 데이터의 기술통계를 살펴보고, 위도(lat)와 경도(lon)의 평균값을 지도의 중심점으로 삼고, 지도의 배율은 14로 하겠습니다.
ansan_data.describe()
| 177279.000000 | 177279.000000 | 177279.000000 | 177279.000000 |
| 147.501768 | 0.618827 | 126.807102 | 37.318794 |
| 199.578856 | 3.144173 | 0.033800 | 0.013132 |
| 1.000000 | 0.000000 | 126.344671 | 37.110933 |
| 32.000000 | 0.000000 | 126.790920 | 37.310979 |
| 80.000000 | 0.000000 | 126.813747 | 37.318522 |
| 171.000000 | 0.000000 | 126.829125 | 37.326330 |
| 4933.000000 | 90.000000 | 127.259800 | 37.407577 |
- 아래와 같이 지도의 중심점을 설정하면, 안산시 단원구 지도가 나오는 것을 볼수 있습니다.
f_lon=126.813232
f_lat=37.318579
Parameters
location(tuple or list, default None) – 위도, 경도로 지도의 중심점을 지정합니다.
zoom_start (int, default 10) – 지도의 배율 지정, 숫자가 커질수록 배율이 낮음
#실습 코드 - 지도를 그리세요 (구글 지도에서 본인이 살고 있는 집 주소를 검색하고 좌표를 찾아서 지도에 띄워 보세요(구글맵 이용))
map = folium.Map(location=[f_lat,f_lon],default=5)
map
folium 패키지는 기존적으로 Open Street Map 기반이지만, Stamen Terrain’, ‘Stamen Toner’, ‘Mapbox Bright’, 와 ‘Mapbox Control room tiles’ 형식을 지정할 수 있습니다.
(Mapbox 의 경우에는 API key가 필요)
map_ST = folium.Map(location=[f_lat,f_lon], zoom_start=14, tiles='Stamen Terrain')
map_ST
ii) 지도위에 데이터 올리기
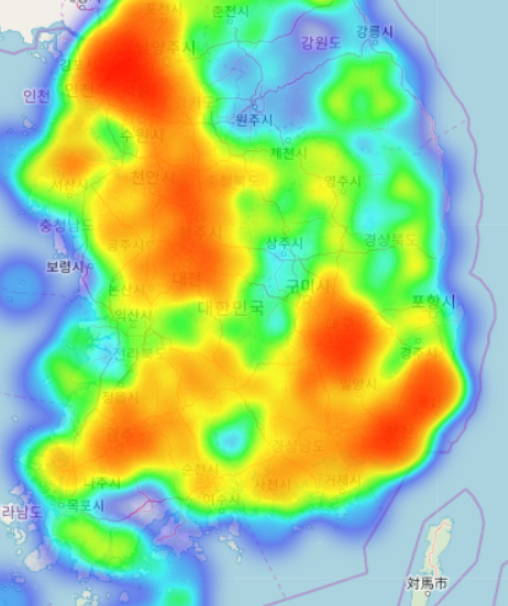
우리는 다양한 지도중에서도 HeatMap을 사용합니다.
Heatmap은 아래와 같이 데이터의 밀도와 분포를 표현하는데 적합합니다
from folium.plugins import HeatMap
개인/개인사업자/법인으로 구분합니다.
ansan_map_1=ansan_data.loc[ansan_data['TYPE']=='개인',:]
ansan_map_2=ansan_data.loc[ansan_data['TYPE']=='개인사업자',:]
ansan_map_3=ansan_data.loc[ansan_data['TYPE']=='법인',:]
Parameter
data (list of points of the form [lat, lng] or [lat, lng, weight]) - numpy.array 또는 list로 입력
min_opacity (default 1.) – 불투명도
max_zoom (default 18) – 최대 밀도에 도달하는 Zoom 레벨
radius (int, default 25) – 포인트의 반경
- 개인의 분포를 확인합니다.
heat_data=np.array([ansan_map_1['lat'],ansan_map_1['lon']])
heat_data=heat_data.transpose() #array의 행열 전환
heat_data
array([[ 37.32558955, 126.82132713],
[ 37.31990483, 126.83285282],
[ 37.31900046, 126.83144718],
...,
[ 37.32312757, 126.78666357],
[ 37.32386146, 126.78701723],
[ 37.31735054, 126.84126659]])map = folium.Map(location=[f_lat,f_lon], zoom_start=13)
HeatMap(heat_data,min_opacity=0.2,max_val=1,max_zoom=25,radius=25).add_to(map)
<folium.plugins.heat_map.HeatMap at 0x7fec18fc7e80>map
개인은 아파트단지 등 주택지역에 많이 분포하는 것을 볼수 있습니다.
- 개인사업자의 분포를 확인합니다
#실습 코드 - 개인에 대해 지도에 heatmap을 그렸던 코드를 참고하여 개인사업자의 데이터를 만듭니다.
heat_data=np.array([ansan_map_2['lat'],ansan_map_2['lon']])
heat_data=heat_data.transpose() #array의 행열 전환
#실습 코드 - 개인에 대해 지도에 heatmap을 그렸던 코드를 참고하여 개인사업자의 분포를 표시합니다.
map = folium.Map(location=[f_lat,f_lon], zoom_start=13)
HeatMap(heat_data,min_opacity=0.2,max_val=1,max_zoom=25,radius=25).add_to(map)
<folium.plugins.heat_map.HeatMap at 0x7fec18a1f0b8>map
- 법인의 분포를 확인합니다
#실습 코드 - 개인에 대해 지도에 heatmap을 그렸던 코드를 참고하여 법인의 데이터를 만듭니다.
heat_data=np.array([ansan_map_3['lat'],ansan_map_3['lon']])
heat_data=heat_data.transpose() #array의 행열 전환
#실습 코드 - 개인에 대해 지도에 heatmap을 그렸던 코드를 참고하여 법인의 분포를 표시합니다.
map = folium.Map(location=[f_lat,f_lon], zoom_start=13)
HeatMap(heat_data,min_opacity=0.2,max_val=1,max_zoom=25,radius=25).add_to(map)
<folium.plugins.heat_map.HeatMap at 0x7fec18fb6588>map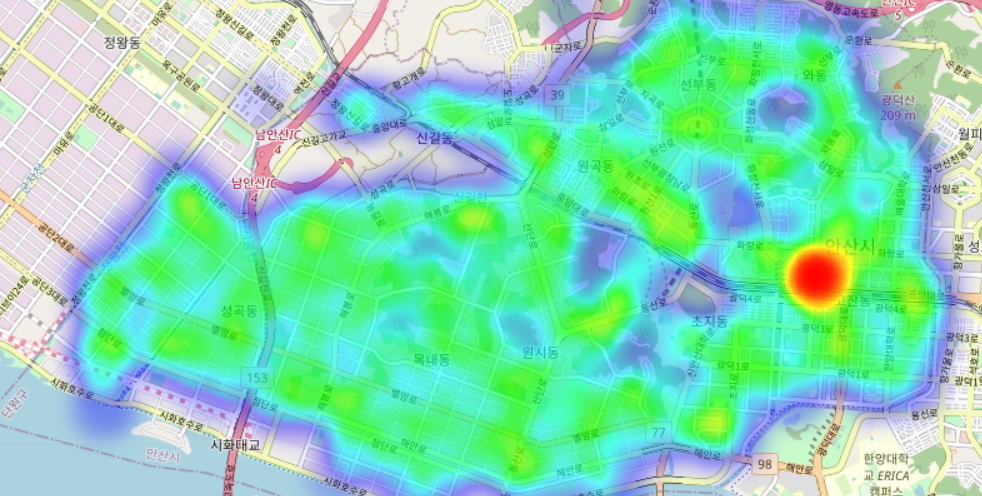
4. 모델링
가. Train/Test 데이터 분할
학습에 사용할 데이터만 남기겠습니다.
ansan_data_T=ansan_data.loc[:,['TYPE','PRODUCT_NM','ROAD_NM','BUILDING_NO1','BUILDING_NO2']]
ansan_data_T.head()
| 개인사업자 | 내선전화 | 도로_300 | 41 | 0 |
| 개인사업자 | 내선전화 | 도로_135 | 215 | 0 |
| 개인사업자 | 내선전화 | 도로_124 | 80 | 0 |
| 개인사업자 | 내선전화 | 도로_139 | 157 | 0 |
| 개인사업자 | 내선전화 | 도로_364 | 29 | 0 |
데이터를 학습에 사용할 데이터와 예측을 위한 데이터로 나누겠습니다.
데이터를 분할 할 때는 Pandas의 sample함수를 이용해서 Train 셋과 Test 셋을 9:1로 분리하겠습니다.
※ 원칙적으로 학습에 사용할 데이터와 예측을 위한 데이터는 전처리 전에 분리해야 합니다.
강의에서 전처리 후에 데이터를 분할한 것은 학습의 편의를 위해서입니다.
#Train set의 크기 계산
N=int(len(ansan_data_T) * 0.9)
#sample 함수를 이용해 Train_set을 분리하여 저장
train_data=ansan_data_T.sample(n=N)
#Train_set을 제외한 나머지를 Test_set으로 저장
test_data=ansan_data_T.drop(ansan_data_T.index[train_data.index])
나. Label Encoding
문자로된 범주형 컬럼들을 숫자로 변경합니다.
train_data
| 법인 | biz_일반전화_A | 도로_109 | 45 | 0 |
| 개인 | 일반전화 | 도로_165 | 9 | 0 |
| 개인사업자 | 내선전화 | 도로_71 | 9 | 0 |
| 개인 | IPTV_E | 도로_271 | 462 | 0 |
| 개인사업자 | 내선전화 | 도로_24 | 16 | 0 |
| ... | ... | ... | ... | ... |
| 법인 | biz_인터넷전화_A | 도로_157 | 234 | 0 |
| 법인 | 일반전화 | 도로_146 | 167 | 10 |
| 법인 | 상품_153 | 도로_271 | 809 | 0 |
| 개인 | 인터넷_A | 도로_190 | 19 | 0 |
| 법인 | 일반전화 | 도로_35 | 88 | 0 |
159551 rows × 5 columns
i) Label Encoding 대상 추출 및 변환
#Label Encoding 대상 컬럼 지정
le_columns=train_data.columns
le_columns
Index(['TYPE', 'PRODUCT_NM', 'ROAD_NM', 'BUILDING_NO1', 'BUILDING_NO2'], dtype='object')범주형 데이터의 범주에 변경이 발생하는 경우가 있습니다.
이런 경우에는 아래와 같이 예외처리를 해주어야 합니다.
from sklearn.preprocessing import LabelEncoder
# #실습 코드 - LabelEncoder를 객체로 생성한 후 , fit( ) 과 transform( ) 으로 label 인코딩 수행.
le = LabelEncoder()
for column in le_columns:
le.fit(train_data[column]) #fitting
train_data[column]=le.fit_transform(train_data[column]) #encoding 적용
if column =='TYPE':
print(le.classes_)
#train_data에 없는 label이 test_data에 있을 수 있으므로 아래 코드가 필요하며, test_data는 fit 없이 transform만 해야함
for label in np.unique(test_data[column]):
if label not in le.classes_: # unseen label 데이터인 경우( )
le.classes_ = np.append(le.classes_, label) # 미처리 시 ValueError발생
test_data[column]=le.transform(test_data[column]) #encoding 적용
[0 1 2]
train_data.shape, test_data.shape
((159551, 5), (17728, 5))※ 모델링 과정에서 Tree 계열 모델을 사용하기 때문에, 교육 중에 One-Hot Encoding은 진행하지 않습니다.
범주형 데이터의 범주가 많은 경우 Tree 계열 모델의 학습속도가 느립니다.
Label Encoding한 데이터를 구분해서 저장합니다.
train_data.shape
(159551, 5)다. Train data와 Validation data 분할
Label Encoding 데이터 분할
- train vs validation 데이터 분리 (feature label 분리)
test_size: test_size의 크기
random_state: random_state를 동일하게 유지해야 일정한 데이터가 나옴
stratify: label을 균등하게 분포하도록 함
train_data
| 2 | 18 | 12 | 44 | 0 |
| 0 | 211 | 74 | 8 | 0 |
| 1 | 21 | 385 | 8 | 0 |
| 0 | 4 | 190 | 347 | 0 |
| 1 | 21 | 156 | 15 | 0 |
| ... | ... | ... | ... | ... |
| 2 | 16 | 65 | 226 | 0 |
| 2 | 211 | 53 | 166 | 10 |
| 2 | 73 | 190 | 391 | 0 |
| 0 | 205 | 102 | 18 | 0 |
| 2 | 211 | 276 | 87 | 0 |
159551 rows × 5 columns
y = train_data.iloc[:,0]
#실습 코드 사이킷런의 train_test_split로 데이터를 train셋과 validation셋으로 분리하세요. (feature와 label을 입력값으로 받습니다. staratify에는 label 값이 들어갑니다.)
from sklearn.model_selection import train_test_split
x_train, x_val, y_train, y_val = train_test_split(train_data.iloc[:,1:],train_data.iloc[:,0] ,test_size=0.2,random_state=21,stratify=train_data.iloc[:,0])
x_train.shape, x_val.shape, y_train.shape, y_val.shape
((127640, 4), (31911, 4), (127640,), (31911,))- test 데이터 feature label 분리
test_data
| 1 | 21 | 102 | 18 | 0 |
| 1 | 21 | 385 | 68 | 0 |
| 1 | 21 | 391 | 165 | 0 |
| 1 | 21 | 292 | 29 | 0 |
| 1 | 21 | 41 | 122 | 0 |
| ... | ... | ... | ... | ... |
| 2 | 16 | 190 | 394 | 0 |
| 2 | 211 | 345 | 23 | 0 |
| 0 | 211 | 320 | 289 | 0 |
| 0 | 205 | 320 | 289 | 0 |
| 0 | 0 | 320 | 289 | 0 |
17728 rows × 5 columns
x_test=test_data.iloc[:,1:]
y_test=test_data.iloc[:,0]
x_test
| 21 | 102 | 18 | 0 |
| 21 | 385 | 68 | 0 |
| 21 | 391 | 165 | 0 |
| 21 | 292 | 29 | 0 |
| 21 | 41 | 122 | 0 |
| ... | ... | ... | ... |
| 16 | 190 | 394 | 0 |
| 211 | 345 | 23 | 0 |
| 211 | 320 | 289 | 0 |
| 205 | 320 | 289 | 0 |
| 0 | 320 | 289 | 0 |
17728 rows × 4 columns
라. 알고리즘 별 학습과 검증
※ 모델별 성능을 저장하기 위한 함수 선언
아래 함수는 외우실 필요없이 저장해두고 Copy 해서 사용하시면 됩니다.
import matplotlib.pyplot as plt
import seaborn as sns
my_predictions = {}
colors = ['r', 'c', 'm', 'y', 'k', 'khaki', 'teal', 'orchid', 'sandybrown',
'greenyellow', 'dodgerblue', 'deepskyblue', 'rosybrown', 'firebrick',
'deeppink', 'crimson', 'salmon', 'darkred', 'olivedrab', 'olive',
'forestgreen', 'royalblue', 'indigo', 'navy', 'mediumpurple', 'chocolate',
'gold', 'darkorange', 'seagreen', 'turquoise', 'steelblue', 'slategray',
'peru', 'midnightblue', 'slateblue', 'dimgray', 'cadetblue', 'tomato'
]
#acc를 구해서 시각화해줌
def acc_eval(name_, pred, actual):
global predictions
global colors
acc = (pred==actual).mean()
my_predictions[name_] = acc
y_value = sorted(my_predictions.items(), key=lambda x: x[1], reverse=False) # 정확도 내림차순으로 sort
df = pd.DataFrame(y_value, columns=['model', 'acc'])
#print(df)
min_ = df['acc'].min() -0.5
max_ = 1.2
length = len(df)
plt.figure(figsize=(10, length))
ax = plt.subplot()
ax.set_yticks(np.arange(len(df)))
ax.set_yticklabels(df['model'], fontsize=15)
bars = ax.barh(np.arange(len(df)), df['acc'])
for i, v in enumerate(df['acc']):
idx = np.random.choice(len(colors))
bars[i].set_color(colors[idx])
ax.text(v+0.1, i, str(round(v, 3)), color='k', fontsize=15, fontweight='bold')
plt.title('Accuracy', fontsize=18)
plt.xlim(min_,max_)
plt.show()
#실수로 잘못 넣은 경우 해당 모델을 삭제
def remove_model(name_):
global my_predictions
try:
del my_predictions[name_]
except KeyError:
return False
return True
#출처: 패스트캠퍼스-직장인을위한 파이썬 데이터분석(이경록) 발췌
i) Decision Tree
Parameter
min_samples_split : 내부 노드를 분할하는데 필요한 최소 샘플 수 (작을 수록 과적합 가능성이 큼)
min_samples_leaf: 리프노드의 최소 샘플 수 (작을 수록 과적합 가능성이 큼)
max_features : 최상의 분할을 찾을 때 고려할 기능의 수
max_depth : 트리의 최대 깊이
max_leaf_nodes : 리프노드의 개수
Step 0. 라이브러리 로딩
#실습 코드 - sklearn의 DecisionTreeClassifier를 로딩합니다.
from sklearn.tree import DecisionTreeClassifier
Step 1. 모델 생성
#실습 코드 - 모델을 생성합니다.
model_dt = DecisionTreeClassifier(min_samples_split=3,
min_samples_leaf=1,
max_features=None,
max_depth=None,
max_leaf_nodes=None
)
Step 2. 모델 학습
#실습 코드 - 모델을 학습합니다.
model_dt.fit(x_train,y_train)
DecisionTreeClassifier(min_samples_split=3)Step 3. 결과 검증
#실습 코드 - 결과를 예측합니다.
pred_dt=model_dt.predict(x_test)
#실습 코드 - acc_eval로 결과를 시각화 합니다.
acc_eval('Decision Tree',pred_dt,y_test)

Step 4. Tree의 구조 확인
n_nodes = model_dt.tree_.node_count
children_left = model_dt.tree_.children_left
children_right = model_dt.tree_.children_right
feature = model_dt.tree_.feature
threshold = model_dt.tree_.threshold
node_depth = np.zeros(shape=n_nodes, dtype=np.int64)
is_leaves = np.zeros(shape=n_nodes, dtype=bool)
stack = [(0, 0)] # start with the root node id (0) and its depth (0)
while len(stack) > 0:
# `pop` ensures each node is only visited once
node_id, depth = stack.pop()
node_depth[node_id] = depth
# If the left and right child of a node is not the same we have a split
# node
is_split_node = children_left[node_id] != children_right[node_id]
# If a split node, append left and right children and depth to `stack`
# so we can loop through them
if is_split_node:
stack.append((children_left[node_id], depth + 1))
stack.append((children_right[node_id], depth + 1))
else:
is_leaves[node_id] = True
print("The binary tree structure has {n} nodes and has "
"the following tree structure:\n".format(n=n_nodes))
for i in range(n_nodes):
if is_leaves[i]:
print("{space}node={node} is a leaf node.".format(
space=node_depth[i] * "\t", node=i))
else:
print("{space}node={node} is a split node: "
"go to node {left} if X[:, {feature}] <= {threshold} "
"else to node {right}.".format(
space=node_depth[i] * "\t",
node=i,
left=children_left[i],
feature=feature[i],
threshold=threshold[i],
right=children_right[i]))iii) Random Forest
Parameter
n_estimators: 결정트리의 수 (bagging에 들어가는 트리의 수)
min_samples_split : 내부 노드를 분할하는데 필요한 최소 샘플 수 (작을 수록 과적합 가능성이 큼)
min_samples_leaf: 리프노드의 최소 샘플 수 (작을 수록 과적합 가능성이 큼)
max_features : 최상의 분할을 찾을 때 고려할 기능의 수
max_depth : 트리의 최대 깊이
max_leaf_nodes : 리프노드의 개수
Step 0. 라이브러리 로딩
#실습 코드 - sklearn에서 RandomForestClassifier를 로드합니다.
from sklearn.ensemble import RandomForestClassifier
Step 1. 모델 생성
#실습 코드 - 모델을 생성하고, 파라미터를 설정합니다.
model_rf= RandomForestClassifier(n_jobs=-1,n_estimators=300,
min_samples_split=2,
min_samples_leaf=1,
max_features='auto',
max_depth=None,
max_leaf_nodes=None)
Step 2. 모델 학습
#실습 코드 - 학습을 진행합니다.
model_rf.fit(x_train,y_train)
RandomForestClassifier(n_estimators=300, n_jobs=-1)Step 3. 결과 검증
#실습 코드 - 결과를 예측합니다.
pred_rf=model_rf.predict(x_test)
#실습 코드 - 결과를 시각화 합니다.
acc_eval('Random Forest',y_test,pred_rf) #기본

iv) XGBoost
Step 0. 라이브러리 로딩
install("xgboost")
#실습코드 - xgboost를 불러옵니다.
import xgboost as xgb
Step 1. 모델 생성
#실습코드 - 모델을 생성합니다. 학습파라미터는 따로 설정하겠습니다.
model_xgb = xgb.XGBClassifier()
Step 2. 모델 학습
- sklearn 래퍼 xgboost 적용
sklearn의 기본 estimator를 이용해 만들어져 앞서 공부한 알고리즘과 사용법이 동일합니다.
그러나, 이 경우 xgboost 학습 성능이 느리기 때문에, 학습이 오래 걸리는 경우에는 사용하기 어렵습니다.
- python 래퍼 xgboost 적용
sklearn을 통하지 않고, 직접 호출을 하면 성능이 더 좋습니다. 이 경우에는 xgboost 공유의 데이터형식인 DMatrix로 변환해주어야 합니다.
#실습 코드 dtrain을 참고해서 validation과 test 데이터도 생성합니다.
# 넘파이 형태의 학습 데이터 세트와 테스트 데이터를 DMatrix로 변환하는 예제
dtrain = xgb.DMatrix(data=x_train, label = y_train)
dval = xgb.DMatrix(data=x_val, label = y_val)
dtest = xgb.DMatrix(data=x_test, label = y_test)
1. Tree Boost Parameter
- eta: learning rate
- num_boost_around: 생성할 weak learner의 수
- min_child_weight: 관측치에 대한 가중치 합의 최소로 과적합 조절 용도 (값이 크면 과적합이 감소)
- gamma:리프 노드에서 추가분할을 만드는데 필요한 최소 손실감소 값(값이 크면 과적합이 감소)
- max_depth:Tree 의 최대 깊이(너무 크면 과적합)
- sub_sample:훈련 중 데이터 샘플링 비율 지정(과적합 제어)
- colsample_bytree: 열의 서브 샘플링 비율
2. Learning Task Parameter
- objective
reg:linear : 회귀 binary:logistic : 이진분류 multi:softmax : 다중분류, 클래스 반환 multi:softprob : 다중분류, 확률 반환 - eval_metric
rmse : Root Mean Squared Error mae : mean absolute error logloss : Negative log-likelihood error : binary classification error rate merror : multiclass classification error rate mlogloss: Multiclass logloss auc: Area Under Curve
#실습 코드 - 파라미터를 설정합니다.
params = {'eta' : 0.3,
'max_depth' : 3,
'min_child_weight':1,
'gamma':0,
'subsample':1,
'colsample_bytree':1,
'objective':'multi:softmax',
'eval_metric':'mlogloss',
'num_class':3}
import time
start=time.time()
early_stopping_rounds 옵션은 XGBoost의 파라미터가 아니고 학습 수행시의 파라미터이므로 XGBClassifier()가 아니라 train()안에 넣어주어야 합니다.
안그러면 아래와 같은 warning이 나오면서 옵션이 사용되지 않습니다.
Parameters: { early_stopping_rounds } might not be used.
#실습 코드
# train 데이터 세트는 'train', validation 데이터 세트는 'eval' 로 명기
wlist = [(dtrain, 'train'), (dval,'eval')]
# 하이퍼 파라미터와 early stopping 파라미터를 train() 함수의 파라미터로 전달
model_xgb = xgb.train(params = params, dtrain=dtrain, num_boost_round=70, evals=wlist,early_stopping_rounds=20,)
(time.time()-start)/60
3.010620717207591Step 3. 결과 검증
#실습 코드 - 결과 예측
pred_xgb=model_xgb.predict(dtest)
#실습 코드 - 결과 시각화
acc_eval('XGBoost',y_test,pred_xgb) #기본

v) Catboost
※도큐먼트: https://catboost.ai/
Parameter
Catboost는 Parameter에 민감하지 않으므로 별도로 설정하지 않겠습니다.
Step 0. 라이브러리 로딩
install('catboost')
#실습 코드
import time
start=time.time()
from catboost import CatBoostClassifier, Pool
Step 1. 모델 생성
#실습 코드 - 모델을 생성하고, 파라미터를 설정합니다.
cat = CatBoostClassifier(learning_rate=0.3,iterations=3000)
Step 2. 모델 학습
#실습 코드 - Pool 함수로 데이터셋을 지정합니다. 반드시 label을 지정해 주어야 합니다.
train_dataset = Pool(data=x_train,label=y_train) #feature와 label 지정
eval_dataset = Pool(data=x_val,label=y_val) #feature와 label 지정
cat.fit(train_dataset, eval_set=eval_dataset,early_stopping_rounds=20)
learning curve 그리기
# retrieve performance metrics
results = cat.evals_result_
# plot learning curves
plt.plot(results['learn']['MultiClass'], label='train')
plt.plot(results['validation']['MultiClass'], label='test')
# show the legend
plt.legend()
# show the plot
plt.show()

(time.time()-start)/60
1.836858073870341Step 3. 결과 검증
#실습 코드 - 결과를 예측합니다.
pred_cat=cat.predict(eval_dataset) #기본
pred_cat
array([[0],
[2],
[0],
...,
[1],
[1],
[0]])y_test
15 1
24 1
28 1
29 1
30 1
..
177260 2
177262 2
177275 0
177276 0
177277 0
Name: TYPE, Length: 17728, dtype: int64pred_cat=pred_cat.reshape(1,-1)[0]
pred_cat
array([0, 2, 0, ..., 1, 1, 0])#실습 코드 - 결과를 시각화 합니다.
acc_eval('Catboost',y_val,pred_cat) #기본

마. 평가지표 활용
i) Confusion Matrix
from sklearn.metrics import confusion_matrix, plot_confusion_matrix
plot=plot_confusion_matrix(cat, x_test,y_test,
display_labels=['개인','개인사업자','법인'],
cmap=plt.cm.Blues)
plot.ax_.set_title('Confusion Matrix')
Text(0.5, 1.0, 'Confusion Matrix')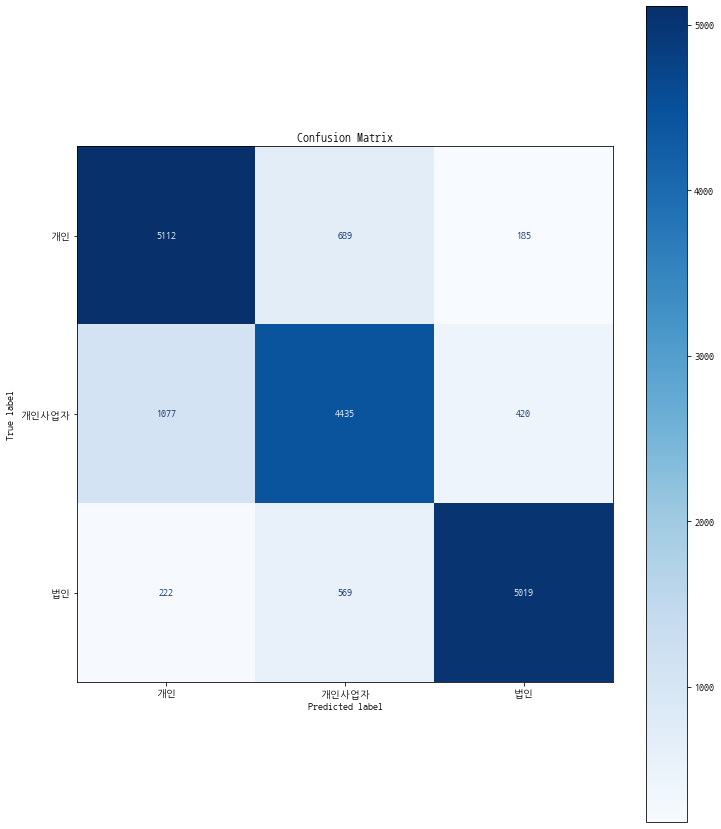
ii) Accuracy/Presision/recall/f1_score
from sklearn.metrics import precision_score, recall_score
from sklearn.metrics import f1_score, accuracy_score
def metric_func(actual,pred):
print("accuracy_score:",accuracy_score(actual,pred))
print("precision_score:",precision_score(actual,pred,average=None))
print("recall_score:",recall_score(actual,pred,average=None))
print("f1_score:",f1_score(actual,pred,average=None))
metric_func(y_test,pred_cat)
iii) ROC Curve & AUC
from sklearn.metrics import roc_curve, auc#Parameter
#y_pred: 원핫인코딩된 2차원 이상의 numpy.array
#y_true: 실제 값
#y_label:label값(list)
def plot_multiclass_roc(y_pred, y_true, y_label):
fpr =dict()
tpr =dict()
roc_auc = dict()
y_test_dummies = pd.get_dummies(y_true, drop_first=False).values
for i in range(len(y_label)):
fpr[i], tpr[i], _ = roc_curve(y_test_dummies[:,i],y_pred[:,i])
roc_auc[i] = auc(fpr[i], tpr[i])
fig, ax = plt.subplots(figsize=(17,10))
ax.plot([0,1],[0,1],'k--')
ax.set_xlim([0.0,1.0])
ax.set_ylim([0.0,1.05])
ax.set_xlabel('False Positive Rate')
ax.set_ylabel('True Positive Rate')
ax.set_title('ROC')
for i in range(len(y_label)):
ax.plot(fpr[i],tpr[i], label = 'ROC curve (area = %0.2f) for label %s' %(roc_auc[i], y_label[i]))
ax.legend(loc='best')
ax.grid(alpha=.4)
sns.despine()
plt.show()
pred_cat
array([0, 2, 0, ..., 1, 1, 0])y_test
15 1
24 1
28 1
29 1
30 1
..
177260 2
177262 2
177275 0
177276 0
177277 0
Name: TYPE, Length: 17728, dtype: int64plot_multiclass_roc(pd.get_dummies(pred_cat).to_numpy(),y_test,['개인','개인사업자','법인'])pd.get_dummies(pred_cat).to_numpy()
array([[1, 0, 0],
[0, 0, 1],
[1, 0, 0],
...,
[0, 1, 0],
[0, 1, 0],
[1, 0, 0]], dtype=uint8)ROC Curve는 개인/개인사업자/법인의 예측 확률을 Threshold로 사용하기 때문에 원핫 벡터 형태의 데이터를 넣으면 그림처럼 각이 생기게 됩니다.
그래서 predict_proba를 쓰면 확률로 표시되는 값을 얻을 수 있고, 이 값을 이용하면 동일한 결과를 얻을 수 있습니다.
pred_cat_proba = cat.predict_proba(x_test)
pred_cat_proba
array([[1.12419020e-03, 9.98722088e-01, 1.53722265e-04],
[2.31345713e-03, 9.97055494e-01, 6.31048586e-04],
[3.90836336e-03, 9.95607040e-01, 4.84596253e-04],
...,
[2.11195572e-01, 6.33518012e-01, 1.55286416e-01],
[2.45785784e-01, 6.14803218e-01, 1.39410999e-01],
[2.82041819e-01, 6.18208448e-01, 9.97497334e-02]])plot_multiclass_roc(pred_cat_proba,y_test,['개인','개인사업자','법인'])
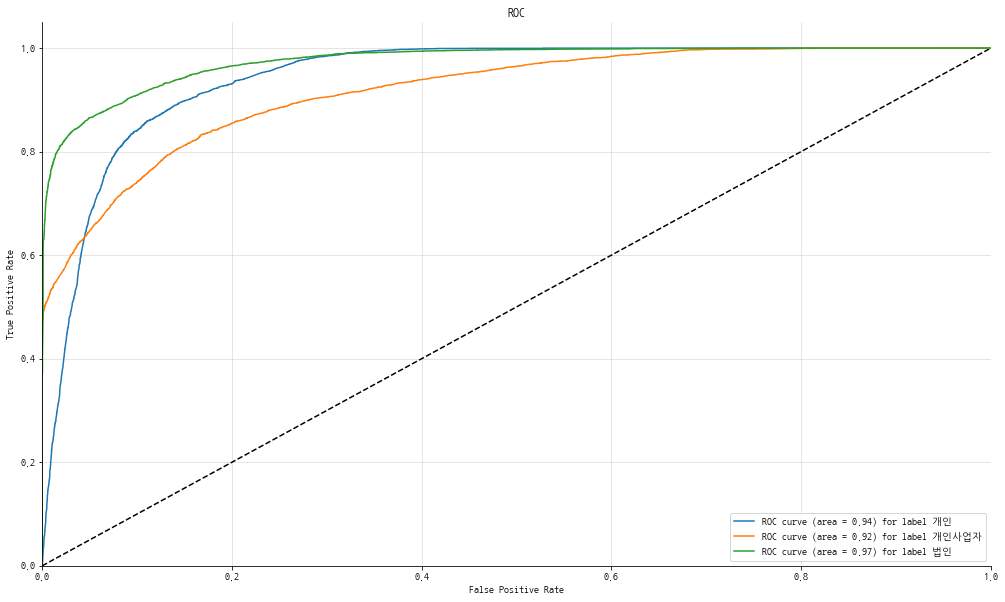
좀더 부드러운 곡선의 ROC Curve를 얻었습니다.
'경기도 인공지능 개발 과정 > Python' 카테고리의 다른 글
| [python] 텐서플로 object_detection 실습 (2) | 2022.08.04 |
|---|---|
| [Ptyhon] 딥러닝 활성화 함수, 가중치 정리 (1) | 2022.07.26 |
| [Python] 텐서플로 손실곡선, 드롭아웃, 모델저장 (0) | 2022.07.17 |
| [Python] 텐서플로_Pooling (0) | 2022.07.13 |
| [Python] 텐서플로_컨볼루전(Conv2D)_실습 (0) | 2022.07.12 |