서브쿼리 분류
서브쿼리에 메인쿼리의 컬럼이 포함되는지에 따라 구분
- 연관 서브쿼리(Correlated Subquery))
- 비연관 서브쿼리(Un-Correlated Subquery)
연관 서브쿼리
메인쿼리의 컬럼이 서브쿼리에 포함되며, 메인쿼리의 컬럼은 서브쿼리에 특정 조건으로 사용된다
SELECT * FROM A
WHERE A.a > (QUERY)
# 메인쿼리의 테이블에 서브쿼리의 조건으로 사용되는 것을 연관서브쿼리라 함
본인이 속한 부서의 평균 급여보다 높은 급여를 받는 직원들을 출력
SELECT ID, DEPARTMENT_ID, NAME, SALARY
FROM EMPLOYEE A
WHERE SALARY >
# 본인이 속한 부서의 평균 급여
(SELECTAVG(SALARY) FROM EMPLOYEE B WHERE B.DEPARTMENT_ID = A.DEPARTMENT_ID);
비연관 서브쿼리
메인쿼리 컬럼이 서브쿼리에 포함되지 않으며, 주로 메인 쿼리에 특정한 값을 제공할 때 사용된다
가장 바깥에 있는 메인쿼리 값에 들어가지 않는 것을 비연관 서브쿼리
ELICE가 속한 부서의 평균 급여를 출력
SELECT AVG(SALARY)
FROM EMPLOYEE
WHERE DEPARTMENT_ID
# DEPARTMENT_ID=1
= (SELECT DEPARTMENT_ID
FROM EMPLOYEE WHERE NAME = ‘ELICE');

반환되는 데이터 형태에 따른 서브쿼리 분류
서브쿼리 분류
- 단일 행 서브쿼리 (Single Row Subquery)
- 다중 행 서브쿼리 (Multi Row Subquery)
- 다중 컬럼 서브쿼리 (Multi Column Subquery)
단일 행 서브쿼리 (Single Row Subquery)
서브쿼리의 결과가 한 개의 행을 반환하며, 단일 행 비교 연산자(=, <, >, <=, >=)와 같이 사용된다
ELICE가 속한 부서의 직원들을 출력
SELECT ID, NAME, SALARY
FROM EMPLOYEE
WHERE DEPARTMENT_ID
# DEPARTMENT_ID = 1
= (SELECT DEPARTMENT_ID FROM EMPLOYEE WHERE NAME = ‘ELICE');

다중 행 서브쿼리(Multi Row Subquery)
서브쿼리의 결과가 두 개 이상 행을 반환할 수 있으며, 다중 행 비교 연산자(IN, ALL, ANY, EXISTS)와 같이 사용된다.
- IN : 서브쿼리 결과에 존재하는 값들 중 하나와 일치해야 한다
- EXISTS : 서브쿼리 결과 값이 존재하는지 여부를 확인한다
- ALL : 서브쿼리 결과에 존재하는 모든 값들에 대해 조건을 만족해야 한다
- ANY : 서브쿼리 결과에 존재하는 값들 중 조건을 만족하는 것이 하나 이상 존재해야 한다
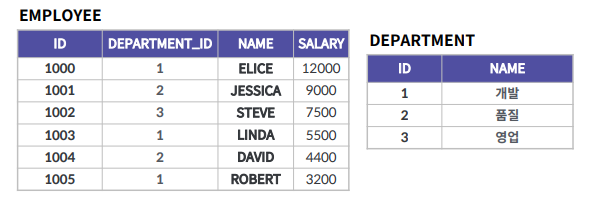
다중 행 서브쿼리 - IN
영업 또는 개발 팀에 속하는 직원들을 출력한다
- IN 연산자를 통해서 해당 값이 포함되냐 되지 않는냐를 판별하여 반환
SELECT NAME
FROM EMPLOYEE
WHERE DEPARTMENT_ID IN
# DEPARTMENT = 1 OR DEPARTMENT = 2
(SELECT ID
FROM DEPARTMENT
WHERE NAME = ‘품질‘ OR NAME = ‘영업’)

다중 행 서브쿼리 - EXISTS
급여가 10000을 넘는 직원이 존재하는 부서에 소속된 모든 직원들을 출력한다.
서브쿼리의 결과가 존재하는지 존재하지 않는지 결과를 보게되며, 특정 값이 아이디가 WHERE문이
만족하는 값이 있기 때문에 첫번째 데이터가 출력이 됨
SELECT NAME
FROM EMPLOYEE A
WHERE EXISTS
(SELECT ID
FROM EMPLOYEE B
WHERE B.SALARY >= 10000 AND A.DEPARTMENT_ID = B.DEPARTMENT_ID);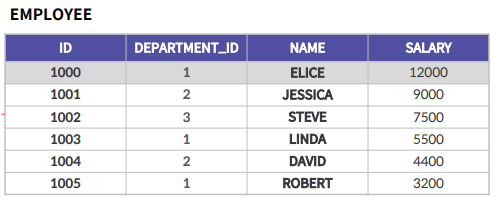

다중 행 서브쿼리 - ALL
- 특정 조건을 모두 만족하는지
개발 팀 소속 모든 직원들 급여보다 급여가 큰 직원들을 출력한다.
SELECT NAME
FROM EMPLOYEE
WHERE SALARY >= ALL
# SALARY 12000, 5500, 3200
(SELECT SALARY FROM EMPLOYEE WHERE
DEPARTMENT_ID = 1);
다중 행 서브쿼리 - ANY
개발 팀 소속 임의의 직원들 급여보다 급여가 큰 직원들을 출력한다.
최소한 하나라도 만족되면 출력이 된다
(아래 조건에서 12000, 5500, 3200 값들 중에서 조건식이 하나라도 만족된다면 전부 출력이 된다.)
SELECT NAME
FROM EMPLOYEE
WHERE SALARY >= ANY
# SALARY 12000, 5500, 3200
(SELECT SALARY
FROM EMPLOYEE
WHERE DEPARTMENT_ID = 1);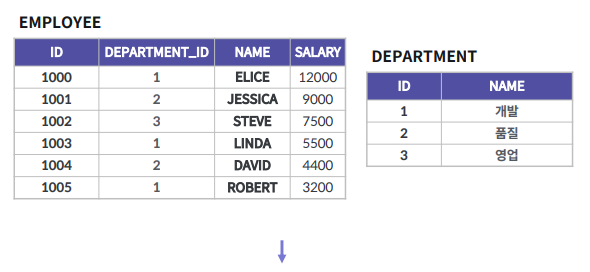

다중 컬럼 서브쿼리
서브쿼리의 결과가 여러 개의 컬럼을 반환하며, 메인쿼리의 조건과 동시에 비교된다.
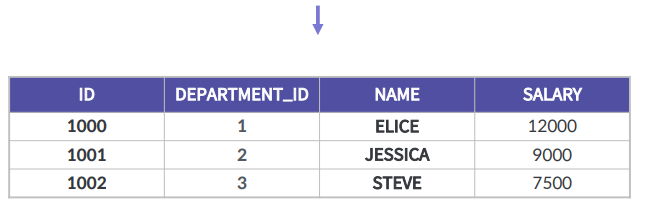
각 부서에서 가장 높은 급여를 받는 직원의 이름과 급여를 출력
컬럼자체가 2개이기 때문에 IN이라는 연산자를 사용했기 때문에 두개의 컬럼이기 때문에
DEPARTMENT_ID를 그룹으로 하여, 그중 가장 높은 SALARY 값들을 반환하게 되고, 메인쿼리 상에는 EMPLOYEE 테이블에서 이 값이 일치하는 직원을 출력
SELECT
NAME, SALARY
FROM EMPLOYEE
WHERE (DEPARTMENT_ID, SALARY) IN
# DEPARTMENT_ID 1,2, 3 SALARY 12000, 9000, 7500
# ID 1000, 1001, 1002, DEPARTMENT_ID 1, 2, 3
(SELECT DEPARTMENT_ID, MAX(SALARY)
FROM EMPLOYEE
GROUP BY DEPARTMENT_ID);
스칼라 서브쿼리
스칼라 서브쿼리는 하나의 속성을 가지면서, 하나의 행만을 반환하는 쿼리이다.(단일행 단일컬럼)
그리고 이는 SELECT, WHERE, HAVING 절 등에서 사용할 수 있다.
부서명과 부서의 구성원 수를 출력한다
SELECT NAME
# DEPARTMENT_ID 1,2,3 COUNT(*) 3,2,1
(SELECT COUNT(*) FROM
EMPLOYEE E WHERE E.DEPARTMENT_ID = D.ID)
FROM DEPARTMENT D;

스칼라 서브쿼리 (DUAL)
FROM을 사용한 특정 테이블 참조 없이 쿼리를 작성하는 경우도 있다. (DUAL은 임시테이블)
ORCLE DB의 경우, 명시를 해줘야 하지만, SQL SERVER 계열은 생략해도 상관이 없다.
전체 임직원 중에 팀장 직급이 차지하는 비율을 출력한다
SELECT
(SELECT COUNT(*) FROM EMPLOYEE WHERE DEPARTMENT_ID = 1) /
(SELECT COUNT(*) FROM EMPLOYEE) AS DEVELOPER_RATIO
FROM
DUAL;
# DEPARTMENT_ID = 1 값이 3개이고 전체의 갯수가 6개이므로 나누면 0.5가 출력된다.
'SQL 이것저것' 카테고리의 다른 글
| [SQL] 윈도우 함수 (0) | 2022.09.14 |
|---|---|
| [SQL] View(뷰) (1) | 2022.09.10 |
| [SQL] JOIN (0) | 2022.08.30 |
| [SQL] 계층형 질의 (2) | 2022.08.30 |
| [SQL] Standard SQL (3) | 2022.08.30 |