데이터 분석을 위한 함수
- 윈도우 함수 (Window fuction)
- 집계 함수 (Aggregate function)
- 그룹 함수 (Group function)
윈도우 함수
- 행과 행간의 관계를 만들어주는 함수 (RANK, DENSE-RANK)
- 순위, 집계 등 행과 행 사이의 관계를 정의하는 함수 OVER 구문을 필수로 한다
SELECT WINDOW_FUNCTION (ARGUMENTS)
OVER ( [PARTITION BY 칼럼] [ORDER BY 절] [WINDOWING 절] ) FROM 테이블 명;- ARGUMENTS : 윈도우 함수에 따라서 필요한 인수
- PARTITION BY : 전체 집합에 대해 소그룹으로 나누는 기준 (특정 컬럼에 대해 기준을 설정해줄 수 있음)
- ORDER BY : 소그룹에 대한 정렬 기준
- WINDOWING : 행에 대한 범위 기준
WINDOWING에 사용되는 인수
- ROWS : 물리적 단위로 행의 집합을 지정
- UNBOUNDED PRECEDING : 윈도우의 시작 위치가 첫 번째 행
- UNBOUNDED FOLLOWING : 윈도우의 마지막 위치가 마지막 행
- CURRENT ROW : 윈도우의 시작 위치가 현재 행
순위 함수
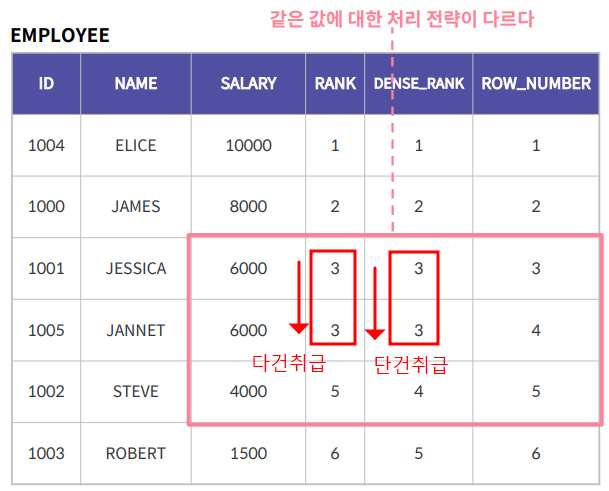
- RANK : 동일한 값에는 동일한 순위를 부여
- DENSE_RANK : RANK와 같이 같은 값에는 같은 순위를 부여하나 한 건으로 취급
- ROW_NUMBER : 동일한 값이라도 고유한 순위를 부여
RANK() OVER ([PARTITION BY 컬럼 ][ORDER BY 컬럼 ][WINDOWING 절] )
SELECT ID, NAME, SALARY,
RANK() OVER (ORDER BY SALARY DESC) RANK,
DENSE_RANK() OVER (ORDER BY SALARY DESC) DENSED_RANKING,
ROW_NUMBER() OVER (ORDER BY SALARY DESC) ROW_NUMBER
FROM EMPLOYEE;기준이 되는 컬럼의 값이 동일할때, RANK의 경우, 다건으로 취급하여 동일한 값을 부여하고, 이후 값을 5로 부여하게 되고 DENSE_RANK는 단건으로 취급하여 다음 값이 4를 부여하게 된다.
일반 집계 함수 (예제)
일반 집계 함수(SUM, AVG, MAX, MIN, …)를 GROUP BY 구문 없이 사용할 수 있다

# 스칼라 서브쿼리를 이용하여 AVG를 구하고 있음
SELECT ID, NAME, SALARY, DEPARTMENT_ID,
(SELECT AVG(SALARY) FROM EMPLOYEE B
WHERE B.DEPARTMENT_ID = A.DEPARTMENT_ID) DEPARTMENT_AVG
FROMEMPLOYEE A
ORDER BY A.DEPARTMENT_ID;↓
# OVER 구문을 통해서 소그룹을 이용하여 DEPARTMENT_AVG를 이용하여 표시함
SELECT ID, NAME, SALARY,
AVG(SALARY) OVER (PARTITION BY DEPARTMENT_ID) DEPARTMENT_AVG
FROM EMPLOYEE;
그룹 내 행 순서 함수
FIRST_VALUE : 가장 먼저 나온 값을 구한다
LAST_VALUE : 가장 나중에 나온 값을 구한다
LAG : 이전 X 번째 행을 가져온다
LEAD : 이후 X 번째 행을 가져온다
FIRST_VALUE, LAST_VALUE
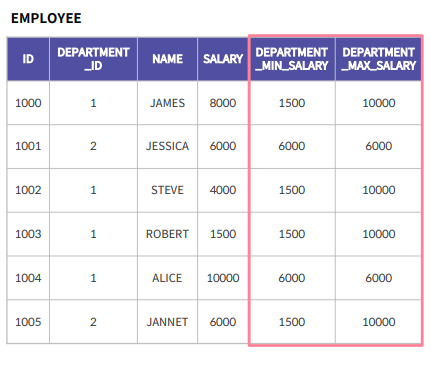
각 부서에서 급여를 가장 많이 받은 사람의 급여와, 가장 적게 받는 사람의 급여를 함께 출력
SELECT
ID, DEPARTMENT_ID, NAME, SALARY,
FIRST_VALUE(SALARY) OVER(PARTITION BY DEPARTMENT_ID ORDER BY SALARY
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) DEPARTMENT_MIN_SALARY ,
LAST_VALUE(SALARY) OVER(PARTITION BY DEPARTMENT_ID ORDER BY SALARY
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) DEPARTMENT_MAX_SALARY
FROM EMPLOYEE
ORDER BY ID;
DEPARTMENT_ID 기준으로 SALARY 값을 보게 되었을 때,
DEPARTMENT_ID 그룹을 형성하고 그 사이
UNBOUNDED PROCEDING 은 첫 값, UNBOUNDED FOLLWING 은 마지막 값을 통해서 최소값과 최대값을 뽑게 된다.
SELECT
ID, DEPARTMENT_ID, NAME, SALARY, FIRST_VALUE(SALARY)
OVER(PARTITION BY DEPARTMENT_ID ORDER BY SALARY
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS DEPARTMENT_MIN_SALARY ,
LAST_VALUE(SALARY)
OVER(PARTITION BY DEPARTMENT_ID ORDER BY SALARY
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
AS DEPARTMENT_MAX_SALARY
FROM EMPLOYEE
ORDER BY ID
UNDERBOUND 절에 CURRENT ROW 절을 넣게된다면, 현재 자신의 절에 대해서 최댓값과 최소값을 구해지게 되기때문에 해당 값으로 변화된다.
SELECT
ID, DEPARTMENT_ID, NAME, SALARY, FIRST_VALUE(SALARY)
OVER(PARTITION BY DEPARTMENT_ID ORDER BY SALARY
ROWS BETWEEN CURRENT ROW PRECEDING AND CURRENT ROW FOLLOWING) AS DEPARTMENT_MIN_SALARY ,
LAST_VALUE(SALARY)
OVER(PARTITION BY DEPARTMENT_ID ORDER BY SALARY
ROWS BETWEEN CURRENT ROW PRECEDING AND CURRENT ROW FOLLOWING)
AS DEPARTMENT_MAX_SALARY
FROM EMPLOYEE
ORDER BY ID

LAG, LEAD
앞/뒤 X번째 행(값)을 불러온다
SELECT ID, NAME, SALARY,
LAG(NAME, 1) OVER(ORDER BY ID) PREV_EMPLOYEE_NAME,
LEAD(NAME, 1) OVER(ORDER BY ID) AFTER_EMPLOYEE_NAME
FROM EMPLOYEE;
그룹 내 비율 함수
RATIO_TO_REPORT : 파티션 내 전체 SUM에 대한 비율을 구한다
PERCENT_RANK : 파티션 내 순위를 백분율로 구한다
CUME_DIST : 파티션 내 현재 행보다 작거나 같은 건들의 수 누적 백분율로 구한다
NTILE : 파티션 내 행들을 N등분한 결과를 구한다
RATIO_TO_REPORT
직원 전체 급여의 합 중 각 행이 차지하는 비율을 출력
SELECT ID, NAME, SALARY,
SUM(SALARY) OVER() TOTAL_SALARY,
RATIO_TO_REPORT(SALARY) OVER() RATIO_TO_REPORT
FROM EMPLOYEE;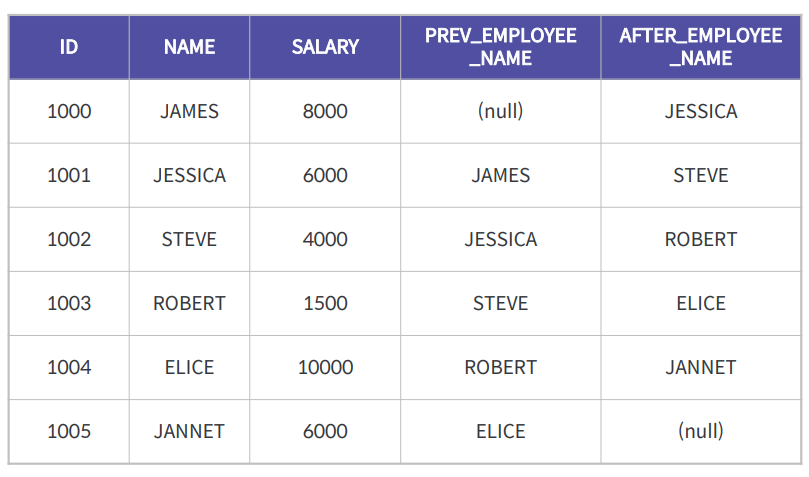
RATIO_TO_REPORT-MariaDB
현재 MariaDB에서 RATIO_TO_REPORT는 제공되지 않기에 명시적으로 구현 가능한다
SELECT ID, NAME, SALARY,
SUM(SALARY) OVER() TOTAL_SALARY,
(SALARY / SUM(SALARY) OVER()) RATIO_TO_REPORT
FROM EMPLOYEE;
PERCENT_RANK, CUME_DIST
PERCENT_RANK는 순위를 백분율로 나타내며 제일 높은 순위 행은 0, 가장 낮은 순위 행은 1을 가진다 CUME_DIST는 현재 행보다 같거나 낮은 값들을 가지는 행들의 누적 백분율 값을 나타낸다.
SELECT ID, NAME, SALARY,
PERCENT_RANK() OVER(ORDER BY SALARY DESC)
AS PERCENT_RANK,
ROUND(CUME_DIST() OVER(ORDER BY SALARY DESC), 4)
AS CUME_DIST
FROM EMPLOYEE;
NTILE(숫자가 오는 것은 몇개의 그룹으로 값을 분류함)
급여에 따라 직원들을 세 그룹으로 분류
SELECT ID, NAME, SALARY,
NTILE(3) OVER(ORDER BY SALARY DESC) NTILE
FROM EMPLOYEE;
'SQL 이것저것' 카테고리의 다른 글
| [SQL] 데이터베이스 준비하기 (0) | 2022.09.16 |
|---|---|
| [SQL] 그룹 함수 (0) | 2022.09.16 |
| [SQL] View(뷰) (1) | 2022.09.10 |
| [SQL] 서브쿼리 (0) | 2022.09.10 |
| [SQL] JOIN (0) | 2022.08.30 |