반응형
그룹 함수란?
데이터를 통계 내기 위해서는, 전체 데이터에 대한 통계는
물론이고 데이터 일부에 대한 소계, 중계 또한 필요
각 레벨 별 SQL을 UNION문 으로 묶어 작성할 수도 있으나
ORACLE DB에서는 이러한 통계 데이터를 위한 몇 가지 함수를 제공

SELECT
D.NAME AS DEPARTMENT_NAME,
J.NAME AS JOB_NAME,
AVG(E.SALARY) AS AVG_SALARY
FROM EMPLOYEE E
JOIN DEPARTMENT D
ON E.DEPARTMENT_ID = D.ID
JOIN JOB J
ON E.JOB_ID = J.ID
GROUP BY
D.NAME, J.NAME
ORDER BY D.NAME, J.NAME;
ROLL UP
그룹화하는 컬럼에 대한 부분적인 통계를 제공
SELECT
D.NAME AS DEPARTMENT_NAME,
J.NAME AS JOB_NAME,
AVG(E.SALARY) AS AVG_SALARY
FROM EMPLOYEE E
JOIN DEPARTMENT D
ON E.DEPARTMENT_ID = D.ID
JOIN JOB J
ON E.JOB_ID = J.ID;
GROUP BY
ROLLUP(D.NAME, J.NAME)
;
ROLL UP ‒ MariaDB
SELECT
D.NAME AS DEPARTMENT_NAME,
J.NAME AS JOB_NAME,
AVG(E.SALARY) AS AVG_SALARY
FROM EMPLOYEE E
JOIN DEPARTMENT D
ON E.DEPARTMENT_ID = D.ID
JOIN JOB J
ON E.JOB_ID = J.ID;
GROUP BY
D.NAME, J.NAME WITH ROLLUP
;
CUBE
ROLLUP 함수에서 제공하는 결과를 포함해서, CUBE 함수에서는 그룹화 하는 컬럼에 대해 결합 가능한 모든 경우의 수에 대해 다차원 집계를 생성
SELECT
D.NAME AS DEPARTMENT_NAME,
J.NAME AS JOB_NAME,
AVG(E.SALARY) AS AVG_SALARY
FROM EMPLOYEE E
JOIN DEPARTMENT D ON E.DEPARTMENT_ID = D.ID
JOIN JOB J ON E.JOB_ID = J.ID
GROUP BY
CUBE(D.NAME, J.NAME);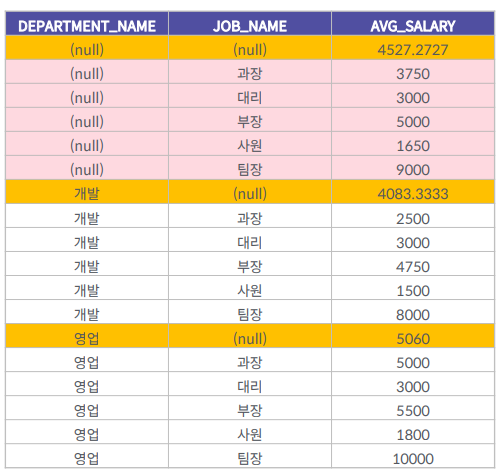
CUBE - MariaDB
SELECT
D.NAME AS DEPARTMENT_NAME,
J.NAME AS JOB_NAME,
AVG(E.SALARY) AS AVG_SALARY
FROM EMPLOYEE E
JOIN DEPARTMENT D ON E.DEPARTMENT_ID = D.ID
JOIN JOB J ON E.JOB_ID = J.ID
GROUP BY
D.NAME, J.NAME WITH ROLLUP
UNION
SELECT
D.NAME AS DEPARTMENT_NAME,
J.NAME AS JOB_NAME,
AVG(E.SALARY) AS AVG_SALARY
FROM EMPLOYEE E
JOIN DEPARTMENT D ON E.DEPARTMENT_ID = D.ID
JOIN JOB J ON E.JOB_ID = J.ID
GROUP BY
J.NAME, D.NAME WITH ROLLUP
;
GROUPING SETS
명시된 컬럼에 대해 개별 통계를 생성한다 각 컬럼에 대해 GROUP BY로
생성한 통계를 모두 UNION ALL한 결과와 동일하다
SELECT
D.NAME AS DEPARTMENT_NAME,
J.NAME AS JOB_NAME,
AVG(E.SALARY) AS AVG_SALARY
FROM EMPLOYEE E
JOIN DEPARTMENT D ON E.DEPARTMENT_ID = D.ID
JOIN JOB J ON E.JOB_ID = J.ID
GROUP BY
GROUPING SETS(D.NAME, J.NAME);
GROUPING SETS - MariaDB
SELECT
D.NAME AS DEPARTMENT_NAME,
NULL,
AVG(E.SALARY) AS AVG_SALARY
FROM EMPLOYEE E
JOIN DEPARTMENT D ON D.ID = E.DEPARTMENT_ID
GROUP BY D.NAME
UNION ALL
SELECT
NULL, J.NAME AS JOB_NAME,
AVG(E.SALARY) AS AVG_SALARY
FROM EMPLOYEE E
JOIN JOB J ON J.ID = E.JOB_ID
GROUP BY J.NAME;
'SQL 이것저것' 카테고리의 다른 글
| [SQL] 정규화 (1) | 2022.09.20 |
|---|---|
| [SQL] 데이터베이스 준비하기 (0) | 2022.09.16 |
| [SQL] 윈도우 함수 (0) | 2022.09.14 |
| [SQL] View(뷰) (1) | 2022.09.10 |
| [SQL] 서브쿼리 (0) | 2022.09.10 |