반응형
- 서울 스타벅스, 이디야 매장데이터를 가지고 옴
- 각각 매장이름, 주소, 구 이름을 판다스로 저장함
패키지 갖고오기
import time
import pandas as pd
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdm_notebook
from selenium import webdriver
from bs4 import BeautifulSoup
from matplotlib import rc
from tqdm import tqdm_notebook
from folium.features import CustomIcon
rc("font", family="Malgun Gothic") # Windows :
# %matplotlib inline
get_ipython().run_line_magic("matplotlib", "inline")
### 스타벅스 매장위치 데이터 가지고 오기

driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get("https://www.starbucks.co.kr/store/store_map.do")
# 지역검색 클릭
driver.find_element_by_css_selector("#container > div > form > fieldset > div > section > article.find_store_cont > article > header.loca_search > h3 > a").click()
time.sleep(1)
# 서울 클릭
driver.find_element_by_css_selector("#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a").click()
time.sleep(1)
# 전체 클릭
driver.find_element_by_xpath('//*[@id="mCSB_2_container"]/ul/li[1]/a').click()
# 해당 페이지 저장
html = driver.page_source
# 해당 페이지 저장
html = driver.page_source
# Beaufiulsoup 사용해서 데이터 불러오기
soup = BeautifulSoup(html, "html.parser")
# 부모태그찾기
starbucks = soup.select("#mCSB_3_container > ul > li")
# 자식태그
# 이름
starbucks[88].select_one("strong").text[:-2]
# 주소
starbucks[88].select_one("p").text
# 구이름
starbucks[88].select_one("p").text.split(" ")[1]## 데이터프레임 만들기
# for 문으로 데이터 프레임 만들기
datas = []
for data in tqdm_notebook(starbucks):
name = data.select_one("strong").text[:-2]
address = data.select_one("p").text
gu_name = data.select_one("p").text.split(" ")[1]
datas.append({
"이름" : name,
"주소" : address,
"구" : gu_name
})
time.sleep(0.5)
driver.quit()
## 데이터프레임으로 저장
df = pd.DataFrame(datas)
df.to_excel("starbucks_seoul_list_.xlsx",encoding="utf-8")
df
### 이디야 매장 데이터 가지고 오기
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get("https://ediya.com/contents/find_store.html#c")# 주소를 클릭
driver.find_element_by_css_selector("#contentWrap > div.contents > div > div.store_search_pop > ul > li:nth-child(2) > a").click()
# 구 는 스타벅스에 있는 구를 활용
# 강서구와 중구는 해당사이트에서 검색량이 많아서 검색이 안됨
# "서울 강서" "서울 중구"로 검색하면 매장검색 가능
# 시간에 따라 분석에서 제외할지 아니면 다른 경로를 통해서 크롤링 할지 정해야함
# 검증을 위해서는 데이터가 많은 구는 넣은게 좋다고 판단됨
gu_list = df["구"].unique()
gu_list = list(gu_list)
gu_list[2] = "서울 강서"
gu_list[-7] = "서울 중구"
gu_list
# 태그분석
# 주소란에 구를 입력
driver.find_element_by_css_selector("#keyword").send_keys(gu_list[0])
# 돋보기를 클릭함
driver.find_element_by_css_selector("#keyword_div > form > button").click()
# soup에다가 현재 창의 주소를 입력함
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
time.sleep(2)
# 부모태그
ediya = soup.select("#placesList > li")
# 이름
print(ediya[0].select_one("dt").text)
# 주소
print(ediya[0].select_one("dd").text)
# 구
print(ediya[0].select_one("dd").text.split(" ")[1])
# 다시 구에 현재 구를 지우고
driver.find_element_by_css_selector("#keyword").clear()
## 구별 데이터를 넣고 데이터 프레임 생성
datas = []
for gugu in tqdm_notebook(range(len(gu_list))):
driver.find_element_by_css_selector("#keyword").send_keys(gu_list[gugu])
driver.find_element_by_css_selector("#keyword_div > form > button").click()
time.sleep(0.5)
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
time.sleep(0.5)
ediya = soup.select("#placesList > li")
time.sleep(0.5)
for data in ediya:
name = data.select_one("dt").text
adress = data.select_one("dd").text
gu = data.select_one("dd").text.split(" ")[1]
datas.append({
"이름" : name,
"주소" : adress,
"구" : gu
})
driver.find_element_by_css_selector("#keyword").clear()
time.sleep(0.5)
driver.quit()# 현재까지 해서 저장
edyia = pd.DataFrame(datas)
edyia.to_excel("edyia_seoul_list.xlsx",encoding="utf-8")## 이디야와 스타벅스 데이터 불러오기
df_starbucks = pd.read_excel("starbucks_seoul_list_.xlsx")
df_starbucks
df_edyia = pd.read_excel("edyia_seoul_list.xlsx")
df_edyia
# 각각 프레임에 브랜드명 추가해주기
df_edyia["브랜드"] = "이디야"
df_starbucks["브랜드"] = "스타벅스"# 하나의 프레임으로 합치기
df = pd.concat([df_edyia, df_starbucks])
df = df.reset_index(drop=True)
df### 해당 위치의 좌표를 불러오기
df["lat"] = np.nan
df["lng"] = np.nan
gmaps_key = "******************************************"
gmaps= googlemaps.Client(key=gmaps_key)
for idx, rows in tqdm_notebook(df.iterrows()):
staion_name = str(rows["브랜드"])+ " " + "서울" + str(rows["이름"])
tmp = gmaps.geocode(staion_name, language="ko")
tmp[0].get("formatted_address")
lat = tmp[0].get("geometry")["location"]["lat"]
lng = tmp[0].get("geometry")["location"]["lng"]
df.loc[idx,"lat"] = lat
df.loc[idx,"lng"] = lng

df_loc.브랜드.value_counts().to_frame()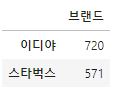
# 서울 시 매장수
df_loc.브랜드.value_counts().plot(kind="bar")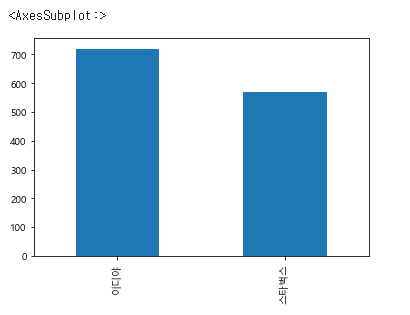
# 전체매장 갯수
df_loc.구.value_counts().to_frame()
# 전체매장 갯수
# 둘다 강남구에 많은 매장을 갖고있고 그다음 중구, 영등포구 등에 가게들이 많이 있음
df_loc.구.value_counts().plot(kind="bar")
#이디야 구 매장 갯수
df_loc[df_loc["브랜드"]=="이디야"]["구"].value_counts().to_frame()
# 구별 이디야 매장 갯수
df_loc[df_loc["브랜드"]=="이디야"]["구"].value_counts().plot(kind="bar")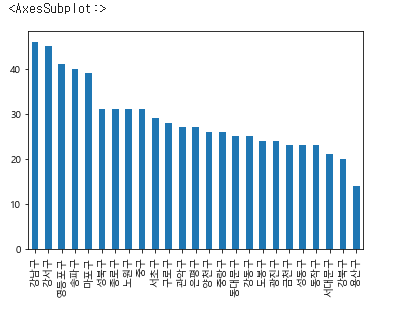
# 구별 스타벅스 매장 갯수
df_loc[df_loc["브랜드"]=="스타벅스"]["구"].value_counts().to_frame()
#스타벅스 구 매장 갯수
df_loc[df_loc["브랜드"]=="스타벅스"]["구"].value_counts().to_frame().plot(kind="bar")
df.groupby("구")["브랜드"].value_counts().to_frame()
- 두 브랜드 다 강남에 가장많은 매장을 가지고 있지만
- 이디야가 스타벅스의 매장전략을 따라간다면 구별 매장의 순위가 비슷해야 되지만 그렇지 않음
# 구별 매장 수 시각화
ediya_loc = df_loc[df_loc["브랜드"]=="이디야"]["구"].value_counts().to_frame()
star_lo = df_loc[df_loc["브랜드"]=="스타벅스"]["구"].value_counts().to_frame()ediya_loc.reset_index()
- 스타벅스와 이디야의 매장별 개장일에 대한정보를 획득할 수 있으면 좀더 구체적인 분석이 가능할 것으로 보임
'파이썬 이것저것 > 크롤링' 카테고리의 다른 글
| [파이썬] 서울시 주유소 크롤링 (0) | 2022.06.05 |
|---|---|
| [파이썬] Naver API 등록해서 사용해보기 (0) | 2022.06.04 |
| [파이썬] 네이버 영화 평점 데이터 분석해보기 (0) | 2022.06.04 |
| [크롤링] GS25 매장 크롤링 -1 (0) | 2022.04.17 |