패키지 설치
install.packages("rvest")
single_table_page <- read_html("single-table.html")
single_table_page
View(single_table_page)

- css 선택자나 xpath 표현식을 사용하여 HTML 노드를 필터링해서 필요한 노드를 선택함
- 필요하지 않은 노드는 생략함
html_table(single_table_page)
html_table(html_node(single_table_page, "table"))
single_table_page %>%
html_node("table") %>%
html_table()

- 문서 내부에 추출할 데이터가 테이블 태그 내에 존재하면 특정 요소를 직접 찾아낼때 사용됨
css 선택자를 사용하여 속성값을 추출함
products_page <- read_html("products.html")
products_page %>%
html_nodes(".product-list li .name")

products_page %>%
html_nodes(".product-list li .name") %>%
html_text()

- 앞 코드에서 html_nodes()는 HTML 노드 집합을 반환
- html_text() 함수는 각 HTML 노드에서 내부 텍스트를 추출하여 문자형 벡터로 반환할 만큼 똑똑함
products_page %>%
html_nodes(".product-list li .price") %>%
html_text()

products <- data.frame(
name = product_items %>%
html_nodes(".name") %>%
html_text(),
price = product_items %>%
html_nodes(".price") %>%
html_text() %>%
gsub("$", "", ., fixed =TRUE) %>%
as.numeric(),
stringsAsFactors = F
)
- CSS 선택자로 웹 페이지에서 데이터 추출하기
- 이 가격 정보는 원래 형식 그대로 여전히 숫자가 아닌 문자열로 표시됨 다음 코드는 동일한 데이터를 추출한 후 좀 더 유용한 형식으로 변환
products

선택된 노드의 중간 결과를 변수로 저장하여 반복적으로 사용할 수 있음
- 그런 다음 이어지는 html_nodes()와 html_text() 함수 호출은 내부 노드에만 해당됨
- 제품 가격은 숫자 값이어야 하므로 gsub() 함수를 사용하여 원가에서 $를 제거한 결과를 숫자 벡터로 변환함
- 파이프라인에서 gsub() 호출은 이전 결과(.로 표시)가 첫 번째 인수가 아닌 세 번째 인수에 들어가야 하므로 다소 특별함
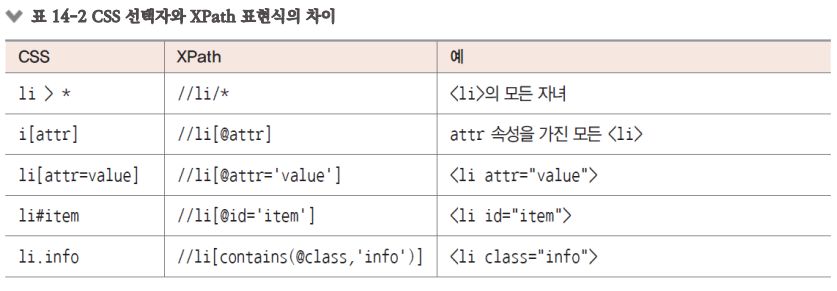
XPath 선택자 학습하기
CSS 선택자는 대부분 HTML 노드를 선택할 수 있다고 할 만큼 강력함
특수한 조건을 충족하는 노드를 선택하려면 때로는 더 강력한 기능이 필요함
다음으로 data/products.html보다 약간 더 복잡한 웹 페이지인 newproducts.html을 살펴보자
page <- read_html("new-products.html")
page

어지럽다 그만알아보자

XPath 선택자 학습하기
- CSS 선택자는 일반적으로 모든 하위 수준의 노드와 일치함
- XPath에서 //와 / 태그는 노드를 서로 다르게 일치하도록 정의함
- // 태그는 모든 하위 수준의 노드를 나타냄
- / 태그는 첫 번째 하위 수준의 노드만 나타냄
page %>% html_nodes(xpath= "//p")

page %>% html_nodes(xpath= "//li[@class]")

page %>% html_nodes(xpath= "//div[@id='list']/ul/li")

page %>% html_nodes(xpath = "//div[@id='list']//li/span[@class='name']")

page %>% html_nodes(xpath = "//div[p]")
<p>를 자녀 노드로 하는 모든 <div>를 선택함

page %>% html_nodes(xpath = "//span[@class='info-value' and text()='Good']")

# 품질이 좋은 제품의 이름을 모두 선택함
page %>%
html_nodes(xpath="//li[div/ul.li[1]/span[@class='info-value' and
text()='Good']]/span[@class='name']")

HTML 코드 분석 및 데이터 추출하기
- 실제 웹 페이지 내용을 긁어 오는 문제는 이제 적절한 CSS, XPath 선택자를 어떻게 작성하는가임 https://cran.rstudio.com/web/packages/available_packages_by_name.html 에서 사용 가능한 모든 R 패키지를 긁어 오려고 한다
- 웹 페이지는 매우 단순함
- 선택자 표현식을 파악하려면 테이블에서 마우스 오른쪽 버튼을 누르고 콘텍스트 메뉴에서 요소 검사(Inspect Element)를 선택함
- 최신 웹 브라우저에서 대부분 사용할 수 있음
페이지 크롤링
url = https://cran.rstudio.com/web/packages/available_packages_by_name.html
CRAN Packages By Name
cran.rstudio.com
# HTML에는 고유한(table)이 포함되어 있으므로 table을 직접 사용하여 선택하거나
# html_table()을 사용하여 데이터 프레임으로 추출 할 수 있음
page <-
read_html("https://cran.rstudio.com/web/packages/available_packages_by_name.html ")
pkg_table <- page %>%
html_node("table") %>%
html_table(fill = TRUE)
head(pkg_table,5)

HTML 코드 분석 및 데이터 추출하기
- 관리자 패널이 나타나고 웹 페이지의 기본 HTML을 볼 수 있음
- 인터넷 익스플로러(Internet Explorer), 파이어폭스(Firefox)나 크롬(Chrome)에서는 선택한 노드를 강조해서 표시하므로 좀 더 쉽게 찾을 수 있음
pkg_table <- pkg_table[complete.cases(pkg_table),]
colnames(pkg_table) <- c("name","title")
head(pkg_table,3)

https://finance.yahoo.com/quote/MSFT
Microsoft Corporation (MSFT) Stock Price, News, Quote & History - Yahoo Finance
Find the latest Microsoft Corporation (MSFT) stock quote, history, news and other vital information to help you with your stock trading and investing.
finance.yahoo.com
MSFT의 최신주가를 추출
HTML 코드 분석 및 데이터 추출하기
계층을 따라 위로 올라가 보면 이 노드로 이동할 수 있는 #quote-header-info div:nth-child(3) span이라는 경로를 찾을 수 있음
이 CSS 선택자를 사용하여 주가를 찾고 추출할 수 있음
page <- read_html("https://finance.yahoo.com/quote/MSFT")
page %>%
html_node("#quote-header-info div:nth-child(3) span") %>%
html_text() %>%
as.numeric()

page %>%
html_node("#quote-summary table") %>%
html_table()

주식 시세 기호(예를 들어 MSFT)가 주어졌을 때 그 회사 이름과 주가를 반환하는 함수를 만들 수 있음
get_price <- function(symbol) {
page <- read_html(sprintf("https://finance.yahoo.com/quote/%s", symbol))
list(symbol = symbol,
company = page %>%
html_node("#quote-header-info div:nth-child(2) h1") %>%
html_text(),
price = page %>%
html_node("#quote-header-info div:nth-child(3) span") %>%
html_text() %>%
as.numeric())
}
get_price("AAPL")

# 또 다른 예는 다음과 같이
# http://stackoverflow.com/questions/tagged/r?sort=votes에서 상위에 있는 R
# 질문을 긁어 오는 것
page <-
read_html("http://stackoverflow.com/questions/tagged/r?sort=votes")
question <- page %>%
html_node("#questions")
questions <- page %>%
html_node("#questions")
questions %>%
html_nodes(".s-post-summary--content-title") %>%
html_text()

questions %>%
html_nodes(".s-link") %>% html_text()

이 모든 것 외에도 rvest 패키지는 페이지 탐색을 시뮬레이션하려고 HTTP 세션 만드는 것을 지원함
자세한 내용은 rvest 설명서를 참고 많은 스크레이핑 작업은 https://selectorgadget.com에서 제공하는 도구를 사용하여 선택자를 쉽게 찾을 수 있음
rvest는 주로 Robobrowser와 BeautifulSoup 같은 파이썬 패키지에서 영감을 얻음
이러한 패키지들은 rvest보다 어떤 면에서는 웹 스크레이핑에서 더 강력하고 인기가 있음 소스가 복잡하고 규모가 클 때는 이러한 파이썬 패키지 사용법을 배우는 것도 좋음
자세한 내용은 https://www.crummy.com/software/BeautifulSoup/을 참고
웹 페이지를 HTML로 작성하고 CSS로 양식화하는 방법을 배움
CSS 선택자를 사용하여 그것과 일치하는 HTML 노드의 내용을 추출할 수 있음
잘 작성된 HTML 문서는 XPath 표현식을 사용하여 쿼리할 수 있음
XPath는 많은 기능을 가지며 더 유연함 최신 웹 브라우저에서 관심 있는 HTML 노드와 일치하는 제한 선택자를 파악하려고 요소 검사기를 사용하는 방법을 배움 이 방법으로 필요한 데이터를 웹 페이지에서 추출할 수 있음
'경기도 인공지능 개발 과정 > R' 카테고리의 다른 글
| R R 마크다운(Rpubs) (0) | 2022.05.02 |
|---|---|
| R 크롤링 - 2 (0) | 2022.04.27 |
| R 웹 크롤링(HTML 기본문법) (0) | 2022.04.26 |
| R 지도시각화 (0) | 2022.04.25 |
| R 비정형 데이터 분석 (0) | 2022.04.25 |