군집 분석이란?
- 각 객체(대상)의 유사성을 측정하여 유사성이 높은 대상 집단을 분류하고, 군집에 속한 객체들의 유사성과 서로 다른 군집에 속한 객체간의 상이성을 규명하는 분석 방법이다.
- 특성에 따라 고객을 여러 개의 배타적인 집단으로 나눈다. - 군집의 개수나 구조에 대한 가정 없이 데이터로부터 거리를 기준으로 군집화를 유도한다.
- 유사성의 거리는 '유클리드 거리'를 이용한다
1. 유클리드 거리
유클리드 거리(Euclidean distance)는 두 점 사이의 거리를 계산하는 방법으로 이 거리를 이용하여 유클리드 공간을 정의한다
<유클리드거리 계산법>
1. 관측 대상의 두 벡터의 차이를 구한다.
2. 각 차의 제곱의 합을 구한다.
3. 제곱근을 취한다.
(1) matrix 생성 x <- matrix(1:9, nrow=3, by=T)
(2) matrix 대상 유클리드 거리 생성 함수 형식)
dist(x, method="euclidean") -> x : numeric matrix, data frame
dist <- dist(x, method="euclidean") # method 생략가능
(3) 유클리드 거리 계산 식
sqrt(sum((x[1,] - x[2,])^2)) # 5.196152
sqrt(sum((x[1,] - x[3,])^2)) # 10.3923
sqrt(sum((x[2,] - x[3,])^2)) # 5.196152
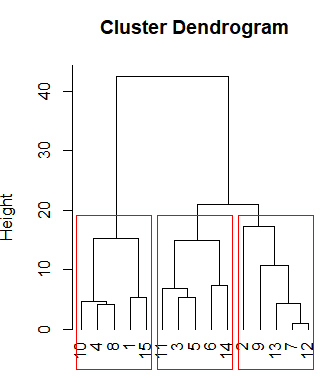
2. 계층적 군집분석
- 계층적 군집분석(Hierarchical Clustering)
- 거리가 가장 가까운 대상부터 결합하여 나무 모양의 계층구조를
- 상향식(Bottom-up)으로 만들어가면서 군집을 형성
body <- read.csv("C:/Users/Admin/Downloads/bodycheck.csv")
body
# 데이터 칼럼보기
names(body)
# 불필요한 칼럼(번호) 제거
body<-body[,-1]
body
# 유클리드 거리 구하기
idist <- dist(body, method = "euclidean")
idist
# hclust()함수를 이용하여 클러스터링
hc<-hclust(idist)
hc

# 클러스터링 시각화 하기
plot(hc, hang=-1) # 움수값 제외

# 3개 그룹 선정, 선 색 지정
rect.hclust(hc,k=3, border="red")
연관 분석이란?
연관 분석은 군집 분석에 의해서 그룹핑 된 cluster를 대상으로 하며 그룹에 대한 특성을 분석하는 방법으로 장바구니 분석으로 알려져 있다.
즉, 유사한 개체들을 클러스터로 그룹화하여 각 집단의 특성 파악하고, 대용량 데이터베이스에서는 전체 데이터를 유사한 클러스터로 묶어서 관찰 및 분석하는 것이 더 효율적이다.
연관 규칙(Association Rule)
- 상업 데이터베이스에서 가장 흔히 쓰이는 도구로,
- 어떤 사건이 얼마나 자주 동시에 발생하는가를 표현하는 규칙(조건)
1. 지지도(support) : 전체자료에서 A를 구매한 후 B를 구매하는 거래 비율
A->B 지지도 식
-> A와 B를 포함한 거래 수 / 전체 거래 수
-> n(A, B) : 두 항목(A,B)이 동시에 포함되는 거래 수
-> n : 전체 거래 수
2. 신뢰도(confidence) : A가 포함된 거래 중에서 B를 포함한 거래의 비율(조건부 확률)
A->B 신뢰도 식
-> A와 B를 포함한 거래수 / A를 포함한 거래수
3. 향상도(Lift) : 하위 항목들이 독립에서 얼마나 벗어나는 지에 대한 정도를 측정한 값
향상도 식
-> 신뢰도 / B가 포함될 거래 비율
분자와 분모가 동일한 경우 : Lift == 1, A와 B가 독립(상관없음)
분자와 분모가 동일한 경우 : Lift != 1, x와 y가 독립이 아닌 경우(상관있음)
install.packages("arules")
library(arules)
data("Groceries")
read.transactions()
# 최대 길이 3이내로 규칙 생성
rules <- apriori(Groceries, parameter = list(supp=0.001, conf=0.80,maxlen=3))
inspect(rules) # 29개 규칙
# confidence(신뢰도) 기준 내림차순으로 규칙 정렬
relues <- sort(rules, decreasing = T, by= "confidence")
inspect(head(relues))
install.packages("arulesViz")
# rules값 대상 그래프를 그리는 패키지
library(arulesViz)
plot(rules, method = "graph", control = list(type="items"))

'경기도 인공지능 개발 과정 > R' 카테고리의 다른 글
| R flexdashborad (0) | 2022.05.04 |
|---|---|
| R Shiny (0) | 2022.05.03 |
| R R 마크다운(Rpubs) (0) | 2022.05.02 |
| R 크롤링 - 2 (0) | 2022.04.27 |
| R 웹 크롤링 (0) | 2022.04.26 |