colnames(customer_r) <- tolower(colnames(customer_r))
colnames(reservation_r) <- tolower(colnames(reservation_r))
colnames(order_info_r) <- tolower(colnames(order_info_r))
colnames(item_r) <- tolower(colnames(item_r))
1. 빈도분석
2. 교차 빈도 분석
3. RFM 분석
4. 상관분석
5. 의사결정나무
6. 분석결과정리
RFM 분석
고객의 미래 구매 행위를 예측하는데 있어 가장 중요한 것이 과거 구매내용이라고 가정하는 시장분석기법임
RFM은 최근의(Recency) 주문 혹은 구매 시점, 특정 기간동안 얼마나 자주(Frequency) 구매하였는가,
구매의 규모는 얼마인가(Moentary Value)를 의미하며,
각 고객에 대한 RFM을 계산후, 이를 바탕으로 고객군을 정의한 뒤 각 고객군의 응답 확률과 발송 비용을 고려해 이익을 주는 고객군에게만 메일을 발송함
Scoring 기법: RFM 요인을 각각 5등급으로 등간격으로 분류하는 방법이다. 현재 개발된 RFM 모형은 크게 4가지로 분류할 수 있다.
모델 1. RFM 각 요소의 20% rule 적용
모델 2. 비율 척도 의한 양적인 정도의 차이에 대한 등간격의 5등급 분류
모델3. 상하 20% 제외한 등간격 척도에 의한 그룹 분류
모델4. 군집 분석에 의한 각 요소 별 5개의 그룹 분류
Data Mining 기법을 이용한 모형
회귀분석
선형 회귀 분석을 이용한 모형
-> 고객의 구매 최근성, 구매 빈도, 구매 금액 등
-> 고갱의 수익 기여도를 나타내는 세가지 지표들의 선형결합으로 세가지 지표들을 점수화 함
다중회귀 분석
-> 각 고객의 구매 행동을 나타내는 R,F,M 변수들을 독립변수로하고,
-> 고객의 미래 구매 행동을 예측하는 기법
신경망을 적용한 모형: 로지스틱 회귀 모형을 보완하는 차원에서 연구
확률적 RFM모형
-> Colmbo와 Weina의 확률적인 RFM모형은
-> 과거의 고객의 응답 이력으로 고객의 미래 응답을 예측하는 행동모델임
이를 바탕으로 맴버쉽 분석을 실시하고자 함
# 지적별 예약 건수 빈도표
table(reservation_r$branch)

가설 : 전체 예약 건과 예약 완료 건 비율 유사할 것임
# 주문 최소되지 않은 경우만 선택
no_cancel_data <- reservation_r %>% filter(cancel == "N")
# 주문 취소되지 않은 예약 건의 부서별 빈도표
table(no_cancel_data$branch)

# 데이터 분석을 위해 원천 데이터 가공(전처리)
# reserv_no를 키로 예약, 주문 테이블 연결
df_f_join_1 <- inner_join(reservation_r, order_info_r, by = "reserv_no")
# item_id를 키로 df_f_join_1, 메뉴 정보 테이블 연결
df_f_join2 <- inner_join(df_f_join_1, item_r, by= "item_id")
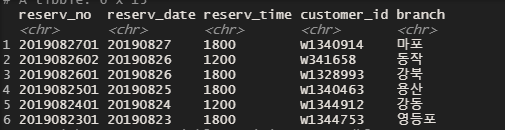
head(df_f_join2)
# 데이터 처리하기
# 강남, 마포, 서초 지점만 선택
df_branch_sales <- df_f_join2 %>%
filter(branch == "강남" | branch == "마포" | branch=="서초") %>%
group_by(branch, product_name) %>%
summarise(sales_amt = sum(sales) / 1000)
df_branch_sales
#
ggplot(df_branch_sales, aes(x = "", y= sales_amt, fill = product_name)) +
facet_grid(facets = . ~ branch) +
geom_bar(stat = "identity")

ggplot(df_branch_sales, aes(x= "", y= sales_amt, fill= product_name)) +
facet_grid(facets = . ~ branch) +
geom_bar(stat = "identity") +
coord_polar("y", start = 0)

분석결과
앞의 과정을 거쳐 매출이 가장 큰 곳은 역시 강남 지저밍며, 각 지점마다 비중은 조금 다르지만 스테이크와 스폐셜 세트 메뉴가 매출의 대부분을 차지하는 것을 알 수 있습니다.
지점별 메뉴 아이템 주문 비율은?
# reserv_no를 키로 예약, 주문 테이블 연결
df_f_join_1 <- inner_join(reservation_r, order_info_r, by="reserv_no")
# 메뉴 정보 테이블 연결
df_f_join2 <- inner_join(df_f_join_1, item_r, by ="item_id")
# 조요 지점만 선택
df_bracnh_items <- df_f_join2 %>% filter(branch=="강남" | branch == "마포" | branch =="서초")
# 교차 빈도표 생성
table(df_bracnh_items$branch, df_bracnh_items$product_name)
# 데이터 프로엠 형태로 구조형 변환
df_bracnh_items_table <- as.data.frame(table(df_bracnh_items$branch, df_bracnh_items$product_name))
# 데이터 분석을 위해 데이터 가공
df_branch_items_percent <- df_bracnh_items_table %>%
group_by(df_bracnh_items_table$Var1) %>%
mutate(percent_items = Freq/sum(Freq) * 100)
head(df_branch_items_percent)
# 데이터 그리기
# 누적 막대 그래프를 그려 gg 변수에 담음
gg <- ggplot(df_branch_items_percent, aes(x=Var1, y= percent_items, group = Var1, fill = Var2)) +
geom_bar(stat="identity")
gg <- gg +
labs(title = "지점별 주문 건수 그래프", x="지점", y="메뉴 아이템 판매비율", fill ="메뉴 아이템")
gg

분석결과
지점별 비율을 100%로 놓고 비교결과를 확인함,
RFM 분석 : 회사의 고객 현황은?
# 테이블 조인
# reserv_no를 키로 예약, 주문 테이블 연결
df_rfm_join_1 <- inner_join(reservation_r, order_info_r, by = "reserv_no")
head(df_rfm_join_1)
# 고객 번호별 방문 횟수 와 매출 정리
df_rfm_data <- df_rfm_join_1 %>%
group_by(customer_id) %>%
summarise(visit_sum = n_distinct(reserv_no), sales_sum = sum(sales) / 1000) %>%
arrange(customer_id)
df_rfm_data # 데이터 확인
summary(df_rfm_data)
# 상자 그림 그리기
ggplot(df_rfm_data, aes(x= "", y = visit_sum)) +
geom_boxplot(width = 0.8, outlier.size = 2, outlier.color = "red") +
labs(title = "방문 횟수 상자그림", x= "빈도", y="방문횟수")
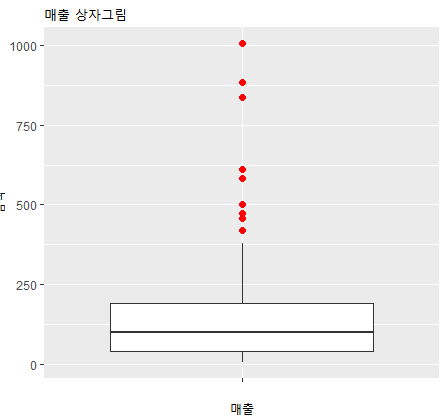
ggplot(df_rfm_data, aes(x = "", y=sales_sum)) +
geom_boxplot(width = 0.8, outlier.size = 2, outlier.colour = "red") +
labs(title = "매출 상자그림", x="매출", y="금액")

# 방문 횟수 60% 와 90% 에 해당하는 분위수 찾기
quantile(df_rfm_data$visit_sum, probs = c(0.6,0.9))

quantile(df_rfm_data$sales_sum, probs = c(0.6,0.9))

# 총 방문 횟수와 총 매출 합
total_sum_data <- df_rfm_data %>%
summarise(t_visit_sum = sum(visit_sum), t_sales_sum = sum(sales_sum))
# 우수 고객 이상의 방문 횟수와 매출 합
loyalty_sum_data <- df_rfm_data %>%
summarise(l_visit_sum = sum(ifelse(visit_sum >2, visit_sum,0)), l_sales_sum = sum(ifelse(sales_sum > 135, sales_sum,0)))
loyalty_sum_data / total_sum_data

# 스테이크와 와인은 관계
# reserve_no를 키로 예약, 주문 테이블 연결
df_f_join_1 <- inner_join(reservation_r, order_info_r, by = "reserv_no")
# item_id를 키로 df_f_join_1, 메뉴 정보 테이블 연결
df_f_join2 <- inner_join(df_f_join_1, item_r, by="item_id")
target_item <- c("M0005","M0009")
# 스테이크와 매뉴 아이템 동시 주문 여부 확인
df_stime_order <- df_f_join2 %>%
filter((item_id %in% target_item)) %>%
group_by(reserv_no) %>%
mutate(order_cnt = n()) %>%
distinct(branch, reserv_no, order_cnt) %>%
filter(order_cnt == 2) %>%
arrange(branch)
# 동시 주문인 경우의 예약 번호 데이터셋
df_stime_order
# 동시에 주문한 예약 번호만 담는 stime_order 변수 생성
stime_order_res_no <- df_stime_order$reserv_no
# 돗이 주문 예약 번호임녀서 스테이크와 와인일 경우만 선택
df_stime_order <- df_f_join2 %>%
filter((reserv_no %in% stime_order_res_no) & (item_id %in% target_item)) %>%
group_by(reserv_no, product_name) %>%
summarise(sales_amt = sum(sales) / 1000) %>%
arrange(product_name, reserv_no)
df_stime_order
steak <- df_stime_order %>% filter(product_name == "STEAK")
wine <- df_stime_order %>% filter(product_name == "WINE")
plot(staek$sales_amt, wine$sales_amt)

#상관관계 확인
cor.test(steak$sales_amt, wine$sales_amt)

# 의사 결정 나무
# 고객별 스테이크 주문 여부 확인
# (A) 모든 고객의 예약 번호 데이터셋 변경
df_rsv_customer <- reservation_r %>%
select(customer_id, reserv_no) %>%
arrange(customer_id, reserv_no)
head(df_rsv_customer)
# (B) 스테이크 주문 예약 번호 데이터셋 생성
df_steak_order_rsv_no <- order_info_r %>%
filter(item_id == "M0005") %>%
mutate(steak_order="Y") %>%
arrange(reserv_no)
head(df_steak_order_rsv_no)
# 고객의 모든 예약 번호(A)에 대해 스테이크 주문한 예약 번호(B)를 레프트 조인
df_steak_order_1 <- left_join(df_rsv_customer, df_steak_order_rsv_no, by= "reserv_no") %>%
group_by(customer_id) %>%
mutate(steak_order = ifelse(is.na(steak_order), "N", "Y")) %>%
summarise(steak_order = max(steak_order)) %>%
arrange(customer_id)
# 최종 정리된 고객별 스테이크 주문 여부
df_dpd_var <- df_steak_order_1
# 종속 변수, 최종 고객 182명의 스테이크 주문 여부 결과 확인
df_dpd_var
# 결측치 제거
df_customer <- customer_r %>% filter(!is.na(sex_code))
# 성별이 없으면(NA) 고객 번호 제거
# 고객 테이블과 예약 테이블 customer_id를 키로 이너 조인
df_table_join_1 <- inner_join(df_customer, reservation_r, by = "customer_id")
# df_table_join_1과 주문 테이블의 reserv_no를 키로 이너 조인
df_table_join_2 <- inner_join(df_table_join_1, order_info_r, by="reserv_no")
str(df_table_join_2)
# 고객 정보, 성별 정보와 방문 횟수, 방문객 수, 매출 합을 요약
df_table_join_3 <- df_table_join_2 %>%
group_by(customer_id, sex_code, reserv_no, visitor_cnt) %>%
summarise(sales_sum = sum(sales)) %>%
group_by(customer_id, sex_code) %>%
summarise(visit_sum = n_distinct(reserv_no), visitor_sum=sum(visitor_cnt), sales_sum=sum(sales_sum)/1000) %>%
arrange(customer_id)
df_idp_var <- df_table_join_3
df_idp_var
# 독립 변수 데이터셋(1-2)에 종속 변수 데이터셋 이너 조인
df_final_data <- inner_join(df_idp_var, df_dpd_var, by = "customer_id")
# 의사결정나무함수를 사용하려고 열 구조를 펙터형으로 바꿈
df_final_data$sex_code <- as.factor(df_final_data$sex_code)
df_final_data$steak_order <- as.factor(df_final_data$steak_order)
df_final_data <- df_final_data[,c(2:6)] # 의사 결정나무에 필요한 열만 선택
df_final_data
install.packages("rpart")
library(rpart)
install.packages("caret")
library(caret)
install.packages("e1071")
library(e1071)
# 난수 생성할때 계속 무작위수가 아닌 1만 번대 값을 고정
set.seed(10000)
# 80% 데이터는 train을 위해 준비, 20%는 test를 위해 준비
train_data <- createDataPartition(y=df_final_data$steak_order, p=0.8, list=FALSE)
train <- df_final_data[train_data,]
test <- df_final_data[-train_data,]
# rpart를 사용해서 의사결정나무 생성
decision_tree <- rpart(steak_order~., data = train)
decision_tree
predicted <- predict(decision_tree, test, type = "class")
confusionMatrix(predicted, test$steak_order)
plot(decision_tree, margin = 0.1)
text(decision_tree)

install.packages("rattle")
library(rattle)
fancyRpartPlot(decision_tree)

'경기도 인공지능 개발 과정 > R' 카테고리의 다른 글
| R flexdashborad (0) | 2022.05.04 |
|---|---|
| R Shiny (0) | 2022.05.03 |
| R 군집분석 & 연관분석 (0) | 2022.05.03 |
| R R 마크다운(Rpubs) (0) | 2022.05.02 |
| R 크롤링 - 2 (0) | 2022.04.27 |