반응형
프로젝트 개요
1. 서울시의 5대범죄에 대한 데이터를 가지고 구별 어떤차이가 있는지 확인해봄
2. GoogleMaps, Folium, Seaborn, Pandas의 피봇테이블 등을 활요아하여 분석해봄

2. 데이터 개요
import numpy as np
import pandas as pd
In [3]:
# 데이터 읽기
crime_raw_data = pd.read_csv("02. crime_in_Seoul.csv", thousands=",", encoding="euc-kr") # thousands 숫자값을 문자로 인식할 수 있어서 설정
crime_raw_data.head()
crime_raw_data.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 65534 entries, 0 to 65533
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 구분 310 non-null object
1 죄종 310 non-null object
2 발생검거 310 non-null object
3 건수 310 non-null float64
dtypes: float64(1), object(3)
memory usage: 2.0+ MBcrime_raw_data["죄종"].unique()- 특정 컬럼에서 unique 조사
- nan 값이 들어가 있다
crime_raw_data[crime_raw_data["죄종"].isnull()].head()
crime_raw_data = crime_raw_data[crime_raw_data["죄종"].notnull()]
In [8]:
crime_raw_data.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 310 entries, 0 to 309
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 구분 310 non-null object
1 죄종 310 non-null object
2 발생검거 310 non-null object
3 건수 310 non-null float64
dtypes: float64(1), object(3)
memory usage: 12.1+ KB
crime_raw_data.head()
crime_raw_data.tail()
3. 서울시 범죄 현황 데이터 정리
crime_station = crime_raw_data.pivot_table(
crime_raw_data,
index="구분",
columns=["죄종", "발생검거"],
aggfunc=[np.sum])
crime_station.head()
crime_station.columns # MultiindexMultiIndex([('sum', '건수', '강간', '검거'),
('sum', '건수', '강간', '발생'),
('sum', '건수', '강도', '검거'),
('sum', '건수', '강도', '발생'),
('sum', '건수', '살인', '검거'),
('sum', '건수', '살인', '발생'),
('sum', '건수', '절도', '검거'),
('sum', '건수', '절도', '발생'),
('sum', '건수', '폭력', '검거'),
('sum', '건수', '폭력', '발생')],
names=[None, None, '죄종', '발생검거'])
crime_station["sum", "건수", "강도", "검거"][:5]구분
강남 26.0
강동 13.0
강북 4.0
강서 10.0
관악 10.0
Name: (sum, 건수, 강도, 검거), dtype: float64
crime_station.columns = crime_station.columns.droplevel([0, 1]) # 다중 컬럼에서 특정 컬럼 제거
crime_station.columnsMultiIndex([('강간', '검거'),
('강간', '발생'),
('강도', '검거'),
('강도', '발생'),
('살인', '검거'),
('살인', '발생'),
('절도', '검거'),
('절도', '발생'),
('폭력', '검거'),
('폭력', '발생')],
names=['죄종', '발생검거'])crime_station.head()
crime_station.indexIndex(['강남', '강동', '강북', '강서', '관악', '광진', '구로', '금천', '남대문', '노원', '도봉',
'동대문', '동작', '마포', '방배', '서대문', '서부', '서초', '성동', '성북', '송파', '수서',
'양천', '영등포', '용산', '은평', '종로', '종암', '중랑', '중부', '혜화'],
dtype='object', name='구분')Index(['강남', '강동', '강북', '강서', '관악', '광진', '구로', '금천', '남대문', '노원', '도봉',
'동대문', '동작', '마포', '방배', '서대문', '서부', '서초', '성동', '성북', '송파', '수서',
'양천', '영등포', '용산', '은평', '종로', '종암', '중랑', '중부', '혜화'],
dtype='object', name='구분')4. Google Maps를 이용한 데이터 정리
In [ ]:
import googlemapsgmaps_key =
gmaps = googlemaps.Client(key=gmaps_key)
In [39]:
gmaps.geocode("서울영등포경찰서", language="ko") # 단순 테스트 코드
tmp = gmaps.geocode("서울영등포경찰서", language="ko")
In [41]:
len(tmp)
Out[41]:
1In [42]:
type(tmp[0].get("geometry")["location"])
Out[42]:
dictIn [43]:
print(tmp[0].get("geometry")["location"]["lat"])
print(tmp[0].get("geometry")["location"]["lng"])
37.5190711
126.9283514
In [44]:
tmp[0].get("formatted_address").split()[2]
Out[44]:
'영등포구'In [45]:
crime_station.head()
- 구별, lat, lng 컬럼
crime_station["구별"] = np.nan
crime_station["lat"] = np.nan
crime_station["lng"] = np.nan
In [47]:
crime_station.head()
- 경찰서 이름에서 소속된 구이름 얻기
- 구이름과 위도 경도 정보를 저장할 준비
- 반복문을 이용해서 위 표의 NaN을 모두 채워줍니다
- iterrows()
count = 0
for idx, rows in crime_station.iterrows():
station_name = "서울" + str(idx) + "경찰서"
tmp = gmaps.geocode(station_name, language="ko")
tmp[0].get("formatted_address")
tmp_gu = tmp[0].get("formatted_address")
lat = tmp[0].get("geometry")["location"]["lat"]
lng = tmp[0].get("geometry")["location"]["lng"]
crime_station.loc[idx, "lat"] = lat
crime_station.loc[idx, "lng"] = lng
crime_station.loc[idx, "구별"] = tmp_gu.split()[2]
print(count)
count = count + 1 crime_station.head()
- 컬럼통합 실시
crime_station.columns.get_level_values(0)[2] + crime_station.columns.get_level_values(1)[2]
Out[50]:
'강도검거'
tmp = [
crime_station.columns.get_level_values(0)[n] + crime_station.columns.get_level_values(1)[n]
for n in range(0, len(crime_station.columns.get_level_values(0)))
]
tmp['강간검거',
'강간발생',
'강도검거',
'강도발생',
'살인검거',
'살인발생',
'절도검거',
'절도발생',
'폭력검거',
'폭력발생',
'구별',
'lat',
'lng']tmp, len(tmp), len(crime_station.columns.get_level_values(0))(['강간검거',
'강간발생',
'강도검거',
'강도발생',
'살인검거',
'살인발생',
'절도검거',
'절도발생',
'폭력검거',
'폭력발생',
'구별',
'lat',
'lng'],
13,
13)crime_station.columns = tmp
In [55]:
crime_station.head()
# 데이터 저장
crime_station.to_csv("crime_in_Seuol_raw.csv", sep=",", encoding="utf-8")
In [61]:
pd.read_csv("crime_in_Seuol_raw.csv").head(2)
7. 구별 데이터로 정리
crime_anal_station = pd.read_csv(
"02. crime_in_Seoul_raw.csv", index_col=0, encoding="utf-8") # index_col "구분"을 인덱스 컬럼으로 설정
crime_anal_station.head()
crime_anal_gu = pd.pivot_table(crime_anal_station, index="구별", aggfunc=np.sum)
del crime_anal_gu["lat"]
crime_anal_gu.drop("lng", axis=1, inplace=True)
crime_anal_gu.head()
# 검거율 생성
# 하나의 컬럼을 다른 컬럼으로 나누기
crime_anal_gu["강도검거"] / crime_anal_gu["강도발생"]구별
강남구 1.076923
강동구 0.928571
강북구 0.800000
관악구 0.894737
광진구 0.545455
구로구 1.300000
노원구 1.500000
도봉구 1.000000
동대문구 1.200000
동작구 1.000000
마포구 1.750000
서대문구 0.800000
서초구 0.769231
성동구 1.666667
성북구 1.000000
송파구 0.800000
양천구 1.000000
영등포구 0.736842
용산구 1.111111
은평구 0.777778
종로구 0.750000
중구 0.875000
중랑구 1.000000
dtype: float64# 다수의 컬럼을 다른 컬럼으로 나누기
crime_anal_gu[["강도검거", "살인검거"]].div(crime_anal_gu["강도발생"], axis=0).head(3)
# 다수의 컬럼을 다수의 컬럼으로 각각 나누기
num = ["강간검거", "강도검거", "살인검거", "절도검거", "폭력검거"]
den = ["강간발생", "강도발생", "살인발생", "절도발생", "폭력발생"]
crime_anal_gu[num].div(crime_anal_gu[den].values).head()
target = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율"]
num = ["강간검거", "강도검거", "살인검거", "절도검거", "폭력검거"]
den = ["강간발생", "강도발생", "살인발생", "절도발생", "폭력발생"]
crime_anal_gu[target] = crime_anal_gu[num].div(crime_anal_gu[den].values) * 100
crime_anal_gu.head()
# 필요 없는 컬럼 제거
del crime_anal_gu["강간검거"]
del crime_anal_gu["강도검거"]
crime_anal_gu.drop(["살인검거", "절도검거", "폭력검거"], axis=1, inplace=True)
crime_anal_gu.head()
# 100보다 큰 숫자 찾아서 바꾸기
crime_anal_gu[crime_anal_gu[target] > 100] = 100
crime_anal_gu.head()
# 컬럼 이름 변경
crime_anal_gu.rename(columns={"강간발생": "강간", "강도발생": "강도", "살인발생": "살인", "절도발생": "절도", "폭력발생": "폭력"},
inplace=True)
crime_anal_gu.head()
8. 범죄 데이터 정렬을 위한 데이터 정리
crime_anal_gu.head()
# 정규화 : 최고값은 1, 최소값은 0
crime_anal_gu["강도"] / crime_anal_gu["강도"].max() 
col = ["살인", "강도", "강간", "절도", "폭력"]
crime_anal_norm = crime_anal_gu[col] / crime_anal_gu[col].max()
crime_anal_norm.head()
# 검거율 추가
col2 = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율"]
crime_anal_norm[col2] = crime_anal_gu[col2]
crime_anal_norm.head()
# 구별 CCTV 자료에서 인구수와 CCTV수 추가
result_CCTV = pd.read_csv("01. CCTV_result.csv", index_col="구별", encoding="utf-8")
result_CCTV.head()
crime_anal_norm[["인구수", "CCTV"]] = result_CCTV[["인구수", "소계"]]
crime_anal_norm.head()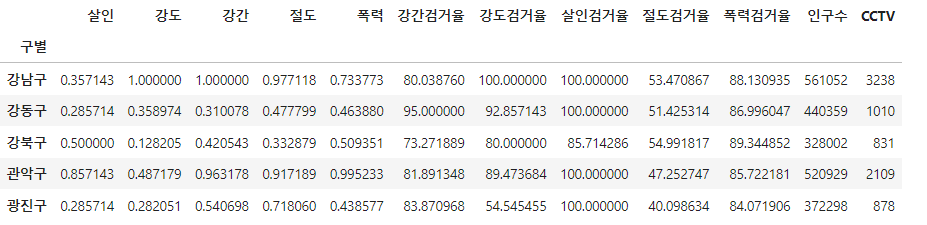
# 정규화된 범죄발생 건수 전체의 평균을 구해서 범죄 컬럼 대표값으로 사용
col = ["강간", "강도", "살인", "절도", "폭력"]
crime_anal_norm["범죄"] = np.mean(crime_anal_norm[col], axis=1)
crime_anal_norm.head()
# 검거율의 평균을 구해서 검거 컬럼의 대표값으로 사용
col = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율"]
crime_anal_norm["검거"] = np.mean(crime_anal_norm[col], axis=1) # axis=1 행을 따라서 연산하는 옵션
crime_anal_norm.head()
서울시 범죄현황 데이터 시각화
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rc
plt.rcParams["axes.unicode_minus"] = False
get_ipython().run_line_magic("matplotlib", "inline")
rc("font", family="Arial Unicode MS") # Windows: Malgun Gothic crime_anal_norm.head()# pairplot 강도, 살인, 폭력에 대한 상관관계 확인
# 해석1. 폭력 사건이 살인으로 이어지는 경우가 강도 사건이 살인으로 이어지는 것 보다 더 많다.
# 해석2. 강도와 폭력은 상관관계가 매우 높다.
sns.pairplot(data=crime_anal_norm, vars=["살인", "강도", "폭력"], kind="reg", height=3);
# "인구수", "CCTV"와 "살인", "강도"의 상관관계 확인
# 해석1-1. 인구수가 증가하는 것에 비해 강도가 많이 증가한다고 볼 수는 없다. (아웃라이어도 존재하며, 이를 제외하면 증가폭은 더욱 줄어들 것이다)
# 해석1-2. 강남3구가 인구수가 많은 곳이라면, 강도 발생 비율이 낮으니까 안전하다고 느낄 수 있지 않을까?
# 해석2-1. 인구수가 증가함에 따라 살인은 증가하는 경향을 보인다.
# 해석2-2. CCTV가 많이 설치되어있을 수록 강도 사건이 많이 일어난다? 이는 해석의 오류. 그렇다면 CCTV가 많아서 강도사건이 많이 발생하니까, CCTV를 줄여야한다 라고 연결될 수 있다.
# 해석2-2. 강도 사건이 많이 발생하는 곳에 CCTV를 많이 설치한 것일 수도 있다.
# 해석2-2. 아웃라이어를 제외하면, 회귀선이 조금 더 내려가서 해석을 달리 할 수 있는 여지가 있다.
def drawGraph():
sns.pairplot(
data=crime_anal_norm,
x_vars=["인구수", "CCTV"],
y_vars=["살인", "강도"],
kind="reg",
height=4
)
plt.show()
drawGraph()
# "인구수", "CCTV"와 "살인검거율", "폭력검거율"의 상관관계 확인
# 해석1-1. 인구수가 증가할 수록 폭력검거율이 떨어진다.
# 해석2-1. 인구수와 살인검거율은 조금 높아지는 것 같은 느낌?
# 해석3-1. CCTV와 살인검거율은 해석하기 애매(100에 모여있는 이유는, 검거율은 100으로 제한했기 때문)
# 해석4-1. CCTV가 증가할수록 폭력검거율이 약간 하향세를 보인다.
def drawGraph():
sns.pairplot(
data=crime_anal_norm,
x_vars=["인구수", "CCTV"],
y_vars=["살인검거율", "폭력검거율"],
kind="reg",
height=4
)
plt.show()
drawGraph()
# "인구수", "CCTV"와 "절도검거율", "강도검거율"의 상관관계 확인
# 해석1-1. CCTV가 증가할수록 절도검거율이 감소하고 있다.
# 해석2-1. CCTV가 증가할수록 강도검거율은 증가하고 있다.
def drawGraph():
sns.pairplot(
data=crime_anal_norm,
x_vars=["인구수", "CCTV"],
y_vars=["절도검거율", "강도검거율"],
kind="reg",
height=4
)
plt.show()
drawGraph()
# 검거율 heatmap
# "검거" 컬럼을 기준으로 정렬
def drawGraph():
# 데이터 프레임 생성
target_col = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율", "검거"]
crime_anal_norm_sort = crime_anal_norm.sort_values(by="검거", ascending=False) # 내림차순
# 그래프 설정
plt.figure(figsize=(10, 10))
sns.heatmap(
data=crime_anal_norm_sort[target_col],
annot=True, # 데이터값 표현
fmt="f", # d: 정수, f: 실수
linewidths=0.5, # 간격설정
cmap="RdPu",
)
plt.title("범죄 검거 비율(정규화된 검거의 합으로 정렬")
plt.show()# 검거를 기준으로 정렬
# 검거율이 높은 곳을 보면, 강남3구가 없다.
drawGraph()
# 범죄발생 건수 heatmap
# "범죄" 컬럼을 기준으로 정렬
def drawGraph():
# 데이터 프레임 생성
target_col = ["살인", "강도", "강간", "절도", "폭력", "범죄"]
crime_anal_norm_sort = crime_anal_norm.sort_values(by="범죄", ascending=False) # 내림차순
# 그래프 설정
plt.figure(figsize=(10, 10))
sns.heatmap(
data=crime_anal_norm_sort[target_col],
annot=True, # 데이터값 표현
fmt="f", # 실수값으로 표현
linewidths=0.5, # 간격설정
cmap="RdPu",
)
plt.title("범죄 비율(정규화된 발생 건수로 정렬)")
plt.show()
# 강남구는 살인을 제외하면, 전부 1등
# 서초구도 상위권에 속함
# 검거율은 낮은데, 범죄 발생 비율이 높다.
# 강남 송파 서초구가 과연 안전할까? 라는 의문을 계속 가질 수 있음
drawGraph()
서울시 범죄현황 지도 데이터 시각화
# 2016년 서울시에서 어느정도 살인사건이 있는가?
# 영등포구에서 살인사건이 제일 많이 일어났다
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles="Stamen Toner")
my_map.choropleth(
geo_data=geo_str,
data=crime_anal_norm["살인"],
columns=[crime_anal_norm.index, crime_anal_norm["살인"]],
fill_color="PuRd",
key_on="feature.id",
fill_opacity=0.7,
line_opacity=0.2,
legend_name="정규화된 살인 발생 건수",
)
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles="Stamen Toner")
my_map.choropleth(
geo_data=geo_str,
data=crime_anal_norm["강간"],
columns=[crime_anal_norm.index, crime_anal_norm["강간"]],
fill_color="PuRd",
key_on="feature.id",
fill_opacity=0.7,
line_opacity=0.2,
legend_name="정규화된 강간 발생 건수",
)
my_map
# 5대 범죄 발생 건수 지도 시각화
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles="Stamen Toner")
my_map.choropleth(
geo_data=geo_str,
data=crime_anal_norm["범죄"],
columns=[crime_anal_norm.index, crime_anal_norm["범죄"]],
fill_color="PuRd",
key_on="feature.id",
fill_opacity=0.7,
line_opacity=0.2,
legend_name="정규화된 5대 범죄 발생 건수",
)
my_map
# 인구대비 범죄 발생 건수
tmp_criminal = crime_anal_norm["범죄"] / crime_anal_norm["인구수"]
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles="Stamen Toner")
my_map.choropleth(
geo_data=geo_str,
data=tmp_criminal,
columns=[tmp_criminal.index, tmp_criminal],
fill_color="PuRd",
key_on="feature.id",
fill_opacity=0.7,
line_opacity=0.2,
legend_name="정규화된 5대 범죄 발생 건수",
)
my_map
# 경찰서별 정보를 범죄발생과 함께 정리
crim_anal_staion = pd.read_csv("02. crime_in_Seoul_1st.csv", encoding="utf-8")
del crim_anal_staion["Unnamed: 0"]col = ["살인검거","강도검거","강간검거","폭력검거","절도검거"]
tmp = crim_anal_staion[col] / crim_anal_staion[col].max() # 정규화 연산
crim_anal_staion["검거"] = np.mean(tmp, axis=1) # numpy axis=1 행 pandas axis =1 열
crim_anal_staion.tail()
# 경찰서 위치 마커 표시
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11)
for idx, rows in crim_anal_staion.iterrows():
folium.Marker(location=[rows["lat"], rows["lng"]]).add_to(my_map)
my_map# 경찰서 위치 마커 표시
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11)
for idx, rows in crim_anal_staion.iterrows():
folium.Marker(location=[rows["lat"], rows["lng"]]).add_to(my_map)
my_map

# 검거에 값을 곱한 뒤에 원의 넓이 적용
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11)
folium.Choropleth(geo_data = geo_str,
data = crime_anal_norm["범죄"],
columns=[crime_anal_norm.index, crime_anal_norm["범죄"]],
key_on = "feature.id",
fill_color = "PuRd",
fill_opacity = 0.7,
line_opacity = 0.2
).add_to(my_map)
for idx, rows in crim_anal_staion.iterrows():
folium.CircleMarker(location=[rows["lat"], rows["lng"]],
radius = rows["검거"] * 50,
popup = rows["구분"] + " : " + "%.2f" % rows["검거"],
color = "#3186cc",
fill= True,
fill_color = "3186cc"
).add_to(my_map)
my_map
서울시 범죄 현황 발생 장소 분석
crime_loc_raw = pd.read_csv("02. crime_in_Seoul_location.csv", thousands=",", encoding="euc-kr")
In [21]:
crime_loc_raw.tail(2)
crime_loc_raw.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 65 entries, 0 to 64
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 범죄명 65 non-null object
1 장소 65 non-null object
2 발생건수 65 non-null int64
dtypes: int64(1), object(2)
memory usage: 1.6+ KBcrime_loc_raw.범죄명.unique()
Out[23]:
array(['살인', '강도', '강간.추행', '절도', '폭력'], dtype=object)In [24]:
crime_loc_raw["장소"].unique()
Out[24]:
array(['아파트, 연립 다세대', '단독주택', '노상', '상점', '숙박업소, 목욕탕', '유흥 접객업소', '사무실',
'역, 대합실', '교통수단', '유원지 ', '학교', '금융기관', '기타'], dtype=object)In [25]:
crime_loc = crime_loc_raw.pivot_table(index = "장소", columns = "범죄명", aggfunc=[np.sum]
)
crime_loc.columns 
col = ["살인","강도","강간","절도","폭력"]
crime_loc_norm = crime_loc / crime_loc.max()
crime_loc_norm.head()
crime_loc_norm["종합"] = np.mean(crime_loc_norm, axis=1)
In [28]:
crime_loc_norm.tail()
import matplotlib as plt
from matplotlib import rc
import seaborn as sns
plt.rcParams["axes.unicode_minus"] = False
rc("font", family="Malgun Gothic") # Windows: Malgun Gothic
# %matplotlib inline
get_ipython().run_line_magic("matplotlib", "inline")crime_loc_norm_sort = crime_loc_norm.sort_values("종합", ascending=False)
def drawGraph():
# plt.figure(figsize=(10, 10))
sns.heatmap(crime_loc_norm_sort, annot=True, fmt="f", linewidths=0.5, cmap="RdPu")
plt.title("범죄와 발생 장소")
plt.show()drawGraph()
'파이썬 이것저것 > 파이썬 데이터분석' 카테고리의 다른 글
| [파이썬] 주유소 데이터 분석 (0) | 2022.06.05 |
|---|---|
| [파이썬] 서울 CCTV 데이터 분석해보기 (0) | 2022.06.04 |
| [파이썬] ProPhet을 활용하여 삼성전자 주식 데이터 예측해보기 (0) | 2022.04.23 |
| [파이썬] ProPhet 활용하여 시계열 예측 (0) | 2022.04.23 |
| [파이썬] 수치형 변수의 요약, 기술통계 (0) | 2022.04.23 |