회귀분석이란?
키와 몸무게 데이터가 있다면, 대략 이정도의 몸무게가 될 것이다라는 것을
알 수 있지만, 컴퓨터가 이 데이터를 가지고 얼마나 정확하게 알 수 있을것인가를 봐야함
대학 운동부 학생들의 신체검사 자료
신입생 A가 들어왔다.(키는 175cm이다) 예상 몸무게는 얼마인가?
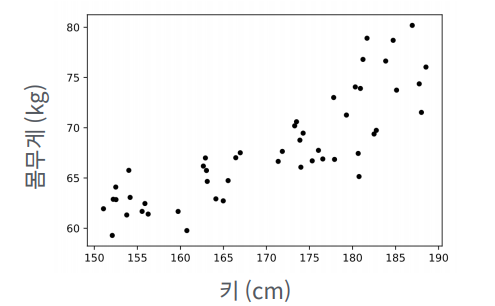
대학 운동부 학생들의 신체검사 자료
신입생 A가 들어왔다.(키는 175cm이다) 예상 몸무게는 얼마인가?

회귀분석법
데이터를 잘 설명하는 선을 찾는 것이며 제품이 판매 됬을 때, 관찰 할 수 없는 외부변인이 많다는 것이고
광고료에 대해서만 정확하게 알아 낼 수 있는지 분석을 실시함,
넓은 범위에서 판매량을 예측할 수 있으나, 기존의 데이터를 가지고 판매량을 예측할 수 있는게 회귀분석법임
데이터: 광고 분석과 판매량
목표: FB 광고에 얼마를 투자하면…상품이 얼마나 팔릴까?
방법: 데이터를 가장 잘 설명하는 어떤 선을 하나 찾는다.

변수 표기
N: 데이터의 개수
X: Input; 데이터/Feature “광고료”
Y: Output; 해답/응답 “판매량”
(x(i), y(i)): i번째 데이터

문제 정의
데이터: N개의 FB 광고 예산과 판매량
목표: 광고에 얼마를 투자했을 때 얼마나 팔릴까?

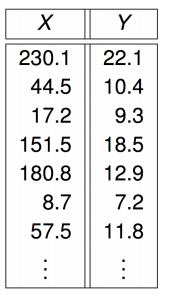


고등학교 수학시간에 y가 판매량이고 X 예산이라면, X는 기울기 이고, B는 절편이라고 배웠음
이 가정은 회귀분석의 가정과 동일함
단순회귀분석 코드
단순 선형회귀 분석 수식은 다음과 같다

import matplotlib as mpl
mpl.use("Agg")
import matplotlib.pyplot as plt
import numpy as np
X = [8.70153760, 3.90825773, 1.89362433, 3.28730045, 7.39333004, 2.98984649, 2.25757240, 9.84450732, 9.94589513, 5.48321616]
Y = [5.64413093, 3.75876583, 3.87233310, 4.40990425, 6.43845020, 4.02827829, 2.26105955, 7.15768995, 6.29097441, 5.19692852]
'''
beta_0과 beta_1 을 변경하면서 그래프에 표시되는 선을 확인
기울기와 절편의 의미를 이해
'''
beta_0 = 0.5 # beta_0에 저장된 기울기 값을 조정
beta_1 = 2 # beta_1에 저장된 절편 값을 조정
plt.scatter(X, Y) # (x, y) 점을 그림
plt.plot([0, 10], [beta_1, 10 * beta_0 + beta_1], c='r') # y = beta_0 * x + beta_1 에 해당하는 선을 그림
plt.xlim(0, 10) # 그래프의 X축을 설정
plt.ylim(0, 10) # 그래프의 Y축을 설정
모델의 학습 목표
기계학습에서 트레이닝 하는것은 B0 과 B1를 찾는 과정이다.
좋은 B0와 B1을 알려줘야 하는데,모델을 잘 트레이닝 하더라도 완벽하지 않더라도 최대한 잘 학습할 수 있도록 차이를 최소화 하는데 그 목적을 가진다.
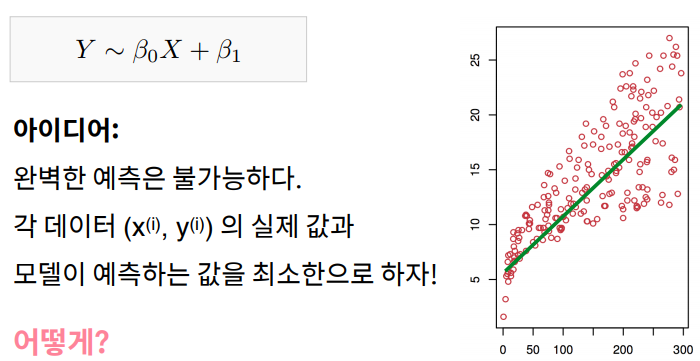
아이디어:
완벽한 예측은 불가능하다.
각 데이터 (x(i), y(i)) 의 실제 값과 모델이 예측하는 값을 최소한으로 하자!
어떤 선을 그었을 때, B0와 B1로 정의가 될 때, B0는 선의 기울기, B1는 절편이라 할 때, 차이를 보고 싶다면, 빨간선은 데이터에 맞는 선이고 나쁜 선일때 차이가 벌어진다.
잘 맞는 선에 비해 차이가 벌어지게 되고 이를 최소화 하는데 목적을 가지고 있음 X1, Y1일 때, 차이를 줄이도록 선을 조정해야 된다.

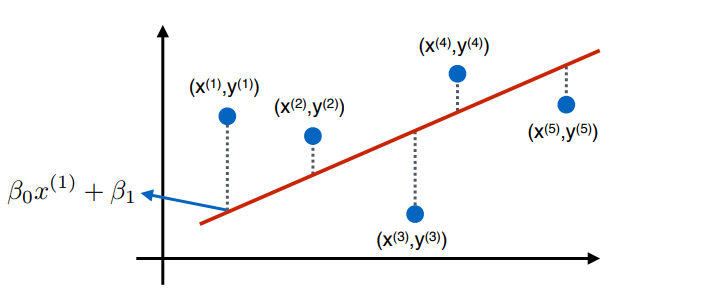
N개의 데이터가 있는데, 이중에서 i번째 데이터가 실제값이 Y 기울기와 예측값이 있을 때, 이 차이는 단순하게 두개의 차이로 볼 수 있는데 차이 값에서 예측값을 빼주는 형태로 만들어준다.
전체 모델의 차이를 나타내는 것은 Summation을 활용하여 나타낸다.

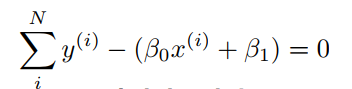
i 번째 데이터의 차이는 이렇게 나타난다. 1부터 N까지 차이를 다 더하는것으로 나타난다. 그런데 이렇게 나타내면 안된다. 만약 다 더하게 된다면 차이가 0이 되기 때문에
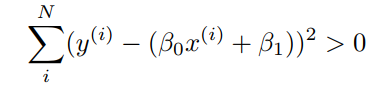
나쁜선을 그릴 때, 실제값에서 예측값을 빼서 더한다면 양수의 차이, 음수의 차이가 있게됨
나쁜선을 그었음에도 음수를 양수로 만들어줘야 되는 방법이 있음
실제값에서 예측값의 차이를 제곱한것을 더하면 해결이 가능하다.

전체 모델의 차이는 실제값에서 예측값의 차이를 제곱하는 것을 전체 모델의 차이가 되서
1부터 N까지 차이를 제곱을 더해서 최소로 만들어 준다면 이를Loss function이라고 하게된다.
Loss function은 L(B0, B1)로 쓰기도 하는데 값을 최소로 만드는 B0과 B1값을 알아내는 거랑 똑같다.

Loss Function
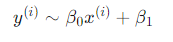
import matplotlib as mpl
mpl.use("Agg")
import matplotlib.pyplot as plt
import numpy as np
def loss(x, y, beta_0, beta_1):
N = len(x)
'''
x, y, beta_0, beta_1 을 이용해 loss값을 계산한 뒤 리턴
'''
x = np.array(x)
y = np.array(y)
y_predicted = beta_0 * x + beta_1
total_loss = 0
total_loss = np.sum((y- y_predicted) ** 2)
# for i in range(N):
# y_i = y[i] # 실제 y(i)
# x_i = x[i] # 실제 x(i)
# y_predicted = beta_0 * x_i + beta_1
# diff = (y_i - y_predicted) ** 2
# total_loss += diff
return total_loss
X = [8.70153760, 3.90825773, 1.89362433, 3.28730045, 7.39333004, 2.98984649, 2.25757240, 9.84450732, 9.94589513, 5.48321616]
Y = [5.64413093, 3.75876583, 3.87233310, 4.40990425, 6.43845020, 4.02827829, 2.26105955, 7.15768995, 6.29097441, 5.19692852]
beta_0 = 1 # 기울기
beta_1 = 0.5 # 절편
print("Loss: %f" % loss(X, Y, beta_0, beta_1))
plt.scatter(X, Y) # (x, y) 점
plt.plot([0, 10], [beta_1, 10 * beta_0 + beta_1], c='r') # y = beta_0 * x + beta_1 에 해당하는 선
plt.xlim(0, 10) # 그래프의 X축을 설정
plt.ylim(0, 10) # 그래프의 Y축을 설정
Lossfunction
산 정상이 되는 지점을 찾고 싶다. 아무 곳에서나 시작했을 때, 가장 정상을 빠르게 찾아가는 방법은?
등산을 할때, 산정상 가는 여러가지 방법이 있다고 하자, 우리의 목표는 가장 빠르게 정상으로 간다고 볼때
B0와 B1를 최적값을 빠르게 찾아내지 못할 경우, 데이터가 유입이 많을 때, 이를 감당하지 못할 것임
그래서 이러한 파라미터를 빠르게 찾아내는 연구가 활발 함

내 위치와 높이를 알고 있다. 어느쪽의 경사가 어디인지만 안다고 할 때,
내 위치에서 경사가 가장 높은쪽으로 가는게 가장 빨리 갈 수 있을 것이다. 이것을 반복하게 된다면 일정 몇 걸음 가고 360도 스캔을 통해서 또 올라가는 형식으로 반복한다면 정상에 다다를 것임

데이터를 가장 잘 설명하는
β0, β1을 구하자 = 예측 값과 실제 값의 차이를 최소로 만드는 값을 구하자 = Loss function을 최소로 만드는 β0, β1을 구하자

L이라는 것은 실제와 예측의 값의 오차를 최소로 하는 값을 찾는게 목표이며, 도자기 같은 모양이 있다고 할 때, B0 B1의 최소값을 알 수 있음

Scikit-learn을 이용한 회귀분석
기계학습 라이브러리 scikit-learn 을 사용하면 Loss Function을 최소값으로 만드는 B0, B1 을 쉽게 구할 수 있음
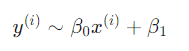
import matplotlib as mpl
mpl.use("Agg")
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LinearRegression
import elice_utils
eu = elice_utils.EliceUtils()
def loss(x, y, beta_0, beta_1):
N = len(x)
x = np.array(x)
y = np.array(y)
total_loss = np.sum((y-(beta_0* x + beta_1)) ** 2)
return total_loss
X = [8.70153760, 3.90825773, 1.89362433, 3.28730045, 7.39333004, 2.98984649, 2.25757240, 9.84450732, 9.94589513, 5.48321616]
Y = [5.64413093, 3.75876583, 3.87233310, 4.40990425, 6.43845020, 4.02827829, 2.26105955, 7.15768995, 6.29097441, 5.19692852]
train_X = np.array(X).reshape(-1, 1)
train_Y = np.array(Y)
'''
모델 트레이닝
'''
lrmodel = LinearRegression()
lrmodel.fit(train_X, train_Y)
'''
loss가 최소가 되는 직선의 기울기와 절편을 계산함
'''
beta_0 = lrmodel.coef_[0] # lrmodel로 구한 직선의 기울기
beta_1 = lrmodel.intercept_ # lrmodel로 구한 직선의 y절편
print("beta_0: %f" % beta_0)
print("beta_1: %f" % beta_1)
print("Loss: %f" % loss(X, Y, beta_0, beta_1))
plt.scatter(X, Y) # (x, y) 점
plt.plot([0, 10], [beta_1, 10 * beta_0 + beta_1], c='r') # y = beta_0 * x + beta_1 에 해당하는 선
plt.xlim(0, 10) # 그래프의 X축을 설정
plt.ylim(0, 10) # 그래프의 Y축을 설정
'파이썬 이것저것 > 파이썬 머신러닝' 카테고리의 다른 글
| [Python] 머신러닝 K-means 클러스터링, PCA(차원축소) (0) | 2022.07.23 |
|---|---|
| [Python] 다중, 다항회귀분석 (1) | 2022.07.18 |
| [파이썬] XGB 활용하여 성적예측 (0) | 2022.04.23 |