# 이미지 분할 (Segmentation)
# 이미지 분할 : 이미지를 구성하는 모든 픽셀에 대하여 픽셀 단위로 분류하는 것.
# 예) 배경 클래스와 객체 클래스로 구성된 이미지가 있다면,
# 모든 픽셀은 배경 또는 객체 중 하나로 분류된다.
# 이렇게 모든 픽셀에 대한 정답 클래스를 레이블 처리한 데이터셋을 가지고,
# 딥러닝 모델을 훈련시키면 정답 클래스를 알지 못하는 새로운 이미지에 대해서도 배경과 객체를 분리할 수 있다.
# 이미지 분할의 종류
# 의미 분할(Semantic Segmentation) : 같은 범주의 여러 객체를 하나의 범주로 묶어서 구분
# 인스턴스 분할 (Instance Segmentation) : 같은 범주에 속하더라도 서로 다른 객체로 구분하는 개념
# Mask R-CNN 논문 => http://kaiminghe.com/iccv17tutorial/maskrcnn_iccv2017_tutorial_kaiminghe.pdf
# 이미지 분할에 사용할 데이터셋 : Oxford-IIT Per Dataset
# => https://www.robots.ox.ac.uk/~vgg/data/pets/
# 이 데이셋은 반려동물의 이미지 및 분류 레이블,
# 각 이미지를 구성하는 픽셀 단위의 마스크로 구성되어 있다.
# 마스크 : 각 픽셀에 대한 범주 레이블을 나타낸다.
# 각 픽셀은 세 가지 범주 중 하나에 속한다.
# class 1 : 반려동물이 속한 픽셀(다음 그림의 노란색 영역)
# class 2 : 반려동물과 인접한 픽셀 (빨간색 영역)
# class 3 : 위에 속하지 않는 경우 / 주변 픽셀 (파란색 영역)
# 영상 처리를 위한 필수 라이블러리를 불러온다
import numpy as np
import tensorflow as tf
import matplotlib.pylab as plt
import cv2
from tqdm.notebook import tqdm
import tensorflow_datasets as tfds
from google.colab.patches import cv2_imshow# 모델 학습에 필요한 입력 이미지의 크기와 학습 파라미터 설정
# 주요 파라미터를 따로 ㅈㅇ리하면 모델의 세부 튜닝 작업이 효율적.
# 이미지 크기
img_w = 128
img_h = 128
img_c = 3
img_shape = (img_w,img_h,img_c)
# 모델 학습
epoch_num = 5
learning_rate = 0.0001
buffer_size = 1000
batch_size = 16
# 텐서플로 데이터셋 로드
# 텐서플로 데이터셋에서 옥스포드 반려동물 데이터를 로딩.
# 메타 정보를 자겨와서 info 변수에 할당(저장).
ds_str='oxford_iiit_pet'
ds, info = tfds.load(name=ds_str, with_info=True)# 원본 이미지와 분할 마스크를 전처리하는 함수 정의
# 이미지를 사전에 정의한 (128, 128)크기로 변경하고 자료형을 변환
# 원본 이미지의 픽셀을 255로 나누어 0~1 범위로 정규화.
# 마스크는 0, 1, 2의 정수 값을 갖도록 1을 차감.
# 이미지 전처리 함수
def preprocess_image(ds):
# 원본 이미지
img = tf.image.resize(ds['image'], (img_w, img_h))
img = tf.cast(img, tf.float32) / 255.0
# 분할 마스크
mask = tf.image.resize(ds['segmentation_mask'], (img_w, img_h))
mask = tf.cast(mask, tf.int32)
mask = mask - 1
return img, mask# 정의한 전처리 함수를 훈련 셋, 테스트 셋에 매핑해주고,
# 미니배치로 분할
# 데이터 전처리 파이프라인
train_ds = ds['train'].map(preprocess_image).shuffle(buffer_size).batch(batch_size).prefetch(2)
test_ds = ds['test'].map(preprocess_image).shuffle(buffer_size).batch(batch_size).prefetch(2)
print(train_ds)# 샘플 배치를 한 개 선택
# 배치에는 16개의 샘플 이미지와 마스크가 들어 있다
img, mask = next(iter(train_ds))
len(img)# 배치에서 첫 번째 이미지를 출력.
# 0~1 사이의 값이므로 255를 곱하여 정규화 이전의 원래값으로 복원
# 샘플 이미지 출력
img = np.array(img[0])*255.0
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
cv2_imshow(img)

# 마스크 이미지를 출력.
# 마스크 값은 0,1,2 이므로 2로 나눈 다음에 255를 곱하면
# RGB 이미지로 표현할 수 있다.
# 샘플 마스크 출력
mask = (np.array(mask[0])/2)*255.0
cv2_imshow(mask)
# U-Net 모델 (인코더/디코더)
# 사전 학습된 VGG16 모델을 인코더로 활용하는 U-Net 모델 구현
# VGG16은 이미지넷 경진대회를 통해 성능이 검증된 모델.
# 데이터 갯수가 충분하고, 시간이 충분하다면
# 사전 학습된 모델 없이 U-Net을 구성하여 학습을 진행해도 된다.
# 구글 코랩 환경에서 제한된 자원으로 양호한 성능을 갖는 모델을 만들기 위해서는
# 사전 학습된 모델을 베이스로 활용하는 전이 학습 방법을 사용.
# VGG16 모델을 최종 레이어를 제외한 채로 불러온다.
base_model = tf.keras.applications.VGG16(input_shape=img_shape, include_top=False)# VGG16 모델 : 합성곱 층과 풀링 층을 직렬로 연결한 구조.
# 모델의 구조를 보면 (128+128) 크기의 텐서가
# 마지막 레이어에서 (4*4)로 축소되는 것을 확인할 수 있다.
# 모델 구조
tf.keras.utils.plot_model(base_model,show_shapes=True)
# 이 모델을 인토더로 사용.
# 인코더 : 원본 이미지 중에서 같은 범주에 속하는 픽셀을 결합하면서 점진적으로 이미지를 더 작은 크기로 축소.
# 즉, 마스크 정답을 활용하여 각 픽셀의 마스크 범주를 0,1,2 중에서 하나로 분류하는 역할.
U-Net 모델 정의
# 1. 만들고자 하는 U-Net의 모양을 미리 정하고,
# 2. 사전 학습된 모델에서 어느 부분의 어떤 shape의 출력을 가져올 지를 먼저 정한다.
# 3. VGG16 모델의 중간 레이어 중에서 필요한 출력 텐서를 지정하여
# 4. 다양한 피처(특징)를 추출하는 인코더 모델을 정의.
# 여기서는 VGG16 모델로부터 5개의 출력을 가져와서 사용.
# 새로운 Feature Extractor 모델을 정의하고,
# f_model 변수에 할당(저장)
# 1개 입력과 5개의 출력을 갖는다.
# VGG16 중간 레이어 출력 텐서를 지정
f_model=tf.keras.Model(inputs=[base_model.input],
outputs=[
base_model.get_layer(name='block5_conv3').output,
base_model.get_layer(name='block4_conv3').output,
base_model.get_layer(name='block3_conv3').output,
base_model.get_layer(name='block2_conv2').output,
base_model.get_layer(name='block1_conv2').output
])# 사전에 학습된 파라미터를 인코더에 그대로 사용하기 위하여
# 업데이트 되지 않도록 고정.
# 파라미터 고정
f_model.trainable = False
# 인코더 부분에서 5개의 출력을 가져와서
# 디코더의 입력으로 전달하면서 업샘플링(Up-Sampling)을 한다
# 업샘플링 : 축소된 이미지를 원래 이미지의 크기로 복원하는 과정.
# 제일 작은 (8,8,512) 텐서에서 시작하여 조금씩 크기를 키워 나가며 중간 출력과 합친다.
# U-Net 구조로 모델 정의
i=tf.keras.Input(shape=img_shape)
out_8_8_512, out_16_16_512, out_32_32_256, out_64_64_128, out_128_128_64 = f_model(i)
out = tf.keras.layers.Conv2DTranspose(512,3,strides=2,padding='same')(out_8_8_512)
out = tf.keras.layers.Add()([out,out_16_16_512])
out = tf.keras.layers.Conv2DTranspose(256,3,strides=2,padding='same')(out)
out = tf.keras.layers.Add()([out,out_32_32_256])
out = tf.keras.layers.Conv2DTranspose(128,3,strides=2,padding='same')(out)
out = tf.keras.layers.Add()([out,out_64_64_128])
out = tf.keras.layers.Conv2DTranspose(64,3,strides=2,padding='same')(out)
out = tf.keras.layers.Add()([out,out_128_128_64])
out = tf.keras.layers.Conv2D(3, 3, activation='elu', padding='same') (out)
out = tf.keras.layers.Dense(3,activation='softmax')(out)
unet_model = tf.keras.Model(inputs=[i], outputs=[out])# U-Net 디코더를 구성할 때
# 입력 텐서와 출력 텐서의 크기를 맞추는 과정이 중요.!!!!
# 여기에서는 인코더의 Conv2D 레이어에 의한 합성곱 변환은
# Conv2DTranpose 레이어를 통해
# 합성곱 연산을 반대 방향으로 되돌릴 수 있다.
# U-Net 모델을 시각화.
# 인코더의 중간 출력이
# 업샘플링 과정에서
# 디코더의 중간 출력과 합쳐지는 것을 확인 할 수 있다.
# 각 레이어의 입출력 텐서 크기를 확인!!!
# 모델 구조 시각화
tf.keras.utils.plot_model(unet_model,show_shapes=True)
# 모델을 요약하면
# 인코더 출력에 사용하기 위해
# f_model로부터 유래하는 5개 레이어의 14,714,688개의 파라미터는 학습되지 않도록 고정되어 있다.
# 모델 요약
unet_model.summary()
# Non-trainable params: 14,714,688
# 예측 클래스의 갯수가 3개인 다중 분류 문제에 맞도록
# SparseCategoricalCrossentropy 손실 함수를 설정하고,
# Adam 옵티마이저를 적용.
# 기본 성능을 확인하는 수준에서 5 epoch 만 훈련 시킨다.
# 모델 컴파일 및 훈련
loss_f = tf.losses.SparseCategoricalCrossentropy()
opt = tf.optimizers.Adam(learning_rate)
unet_model.compile(optimizer=opt, loss=loss_f, metrics=['accuracy'])
unet_model.fit(train_ds, batch_size=batch_size, epochs=epoch_num)# 검증 셋의 배치를 하나 선택하고,
# predict() 함수로 이미지 분할 클래스를 예측한다.
# 배치를 구성하는 16개의 이미지 즁에서 첫 번째 이미지의 분할 결과를 출력.
추론
검증 데이터셋을 모델에 입력하여 이미지 분할 예측
# 1개 배치(16개 이미지)를 선택
img, mask = next(iter(test_ds))
# 모델 예측
pred = unet_model.predict(img)
# 첫번째 이미지 분할 결과를 출력
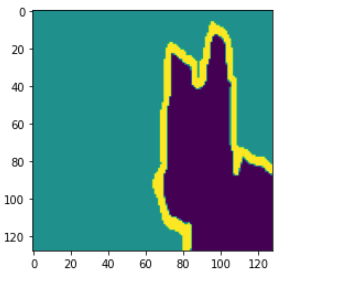
pred_img=np.argmax(pred[0], -1)
plt.imshow(pred_img)
# 정답 마스크 이미지를 출력하고, 예측한 분할 이미지와 비교.
# 어느 정도 객체의 경계를 찾아내는 것을 확인할 수 있다.
# 첫번째 이미지의 정답 마스크 출력
plt.imshow(np.reshape(mask[0], (128,128)))
'경기도 인공지능 개발 과정 > Python' 카테고리의 다른 글
| [AIFB] matplolib, seaborn 시각화 (0) | 2022.08.08 |
|---|---|
| [AIFB] pandas 기초 전처리 (0) | 2022.08.08 |
| [Python] Simple YoLo 실습 (0) | 2022.08.04 |
| [python] 텐서플로 object_detection 실습 (0) | 2022.08.04 |
| [Ptyhon] 딥러닝 활성화 함수, 가중치 정리 (0) | 2022.07.26 |